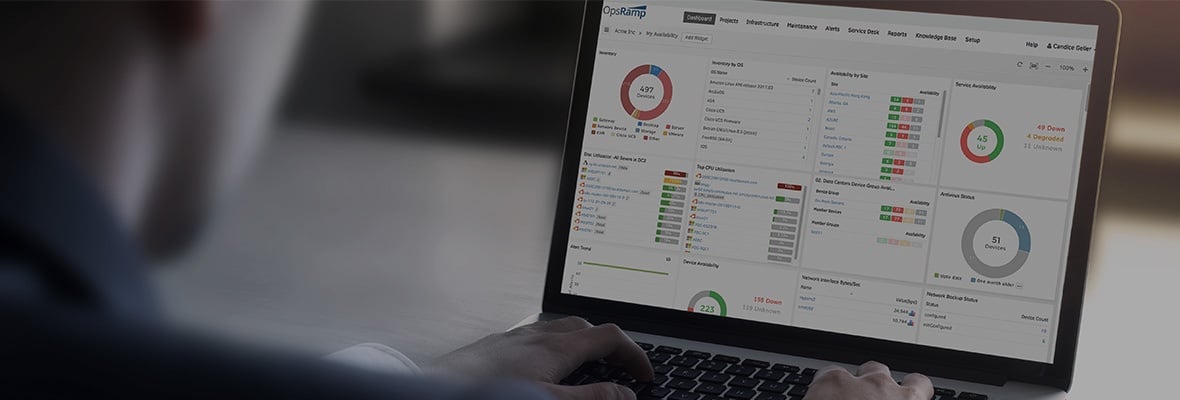


ログやトレースとともに、可観測性の3つの柱の1つとして、メトリックのダイジェストは、ITOps管理者の仕事の重要な部分です。メトリックは、時間間隔で測定されたデータの数値表現であるため、システムの動作に関する知識を過去に導き出すことができます。これにより、将来の動作パターンを予測し、問題やインシデントの調査に情報を提供できます。
監視ツールがメトリックを収集したら、実用的な洞察を作成する次のステップは、ダッシュボードでそれらを視覚化することです。このブログでは、どのタイプのメトリックに対してどのタイプのダッシュボードを作成するかについて、いくつかのヒントを紹介します。見栄えの良いダッシュボードを作成する目的は、異常を簡単に特定して、チームメンバーがより迅速に行動できるようにすることです。適切なチャートを選択すると、これがより合理化されます。ここOpsRampでは、ダッシュボードの作成にオープンソースのクエリ言語であるPrometheusの使用を標準化しています。
Prometheusの短い入門書(PromQL)
PromQLは、DevOpsスペースで急速に人気が高まっており、時系列データの柔軟な操作を可能にするため、コンテナーとマイクロサービスを監視するための標準になりつつあります。 NS プロメテウス クライアントライブラリは、4つのコアメトリックタイプを提供します。各グラフは、これらの指標の特定のタイプにより適しています。
4つのPromQLメトリックタイプは次のとおりです。
- カウンター: 単一の単調に増加するカウンターを表す累積メトリック。その値は、再起動時にのみ増加するか、ゼロにリセットできます。
- ゲージ: 任意に上下できる単一の数値を表すメトリック(CPU使用率など)。
- ヒストグラム: 観測値をサンプリングし、構成可能なバケットでカウントします。すべての観測値の合計を提供することもできます。
- 概要:観測値をサンプリングし、観測値の総数とすべての観測値の合計を提供します。構成可能な分位数は、スライディング時間ウィンドウで計算されます。
可観測性のための一般的なチャートタイプ
適切なオーディエンスに適切なチャートを選択することが重要です。 CXOは、異常を特定して問題を迅速にトラブルシューティングする必要があるIT管理者やDevOpsの人々と比較して、高レベルの情報を必要とします。最もよく使用されるグラフのいくつかと、それぞれについて収集する指標を次に示します。
時系列タイル
OpsRampで定義されているように、時系列タイルまたはウィジェットは、連続する時間間隔でデータポイントを表示します。グラフの各ポイントは、特定の時点と測定されているメトリック値に対応します。データポイントは、接続された折れ線グラフまたは垂直棒グラフの形式で表示できます。
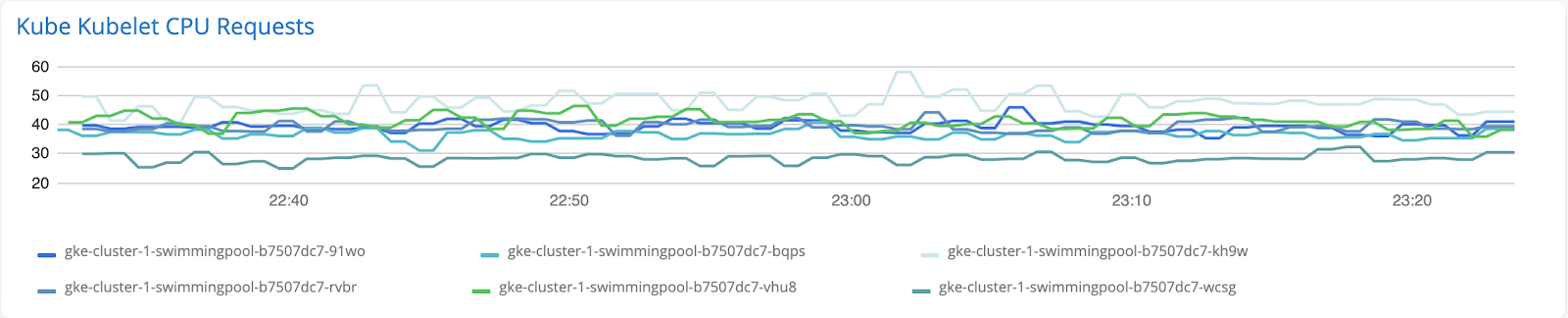
折れ線グラフ
一定期間にわたるメトリック値の変化を追跡するには、折れ線グラフをお勧めします。これらは、単一のグラフで複数のホストまたはリソースの値を表示および比較するための簡単でスキャン可能な方法を提供します。
推奨される指標: ゲージメトリック、例: CPU、メモリ、ディスク、可用性
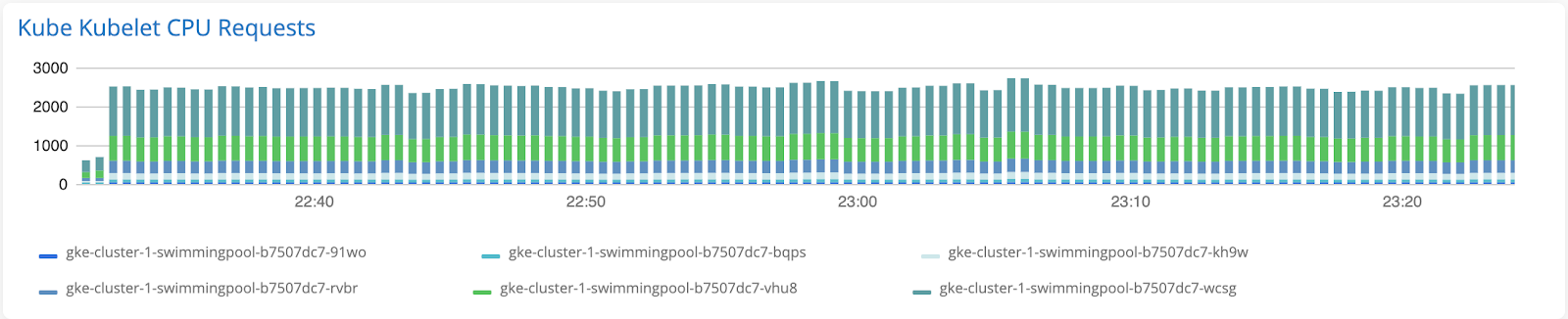
棒グラフ
さまざまなホストまたはリソースのメトリック値を経時的に比較するには、棒グラフをお勧めします。各ホストまたはリソースは、棒グラフでスタックとして表されます。折れ線グラフ(コンボチャート)と組み合わせて棒グラフを使用することをお勧めします。棒グラフは各リソースのメトリック値を表し、折れ線グラフはこれらの値の集計(たとえば、すべてのリソースの平均値)を表します。
推奨される指標: ゲージメトリック、例: CPU、メモリ、ディスク、可用性、またはヒストグラムのメトリック
単一値タイル
単一値タイルには、特定の時点での単一のデータポイントが表示されます。クエリが複数のシリーズを返す場合は、メトリックを集計して、値を1つの単位に統合する必要があります。単一値タイルを使用して、重要な時系列データを要約したり、ITインフラストラクチャの概要を一目で把握したりすることをお勧めします。一部の例には、特定のリソースタイプのカウントや、可用性メトリックの極値の追跡が含まれる場合があります。
推奨される指標:カウンターメトリックまたは任意のメトリックの集計(例:カウント、合計、平均、最小、最大)
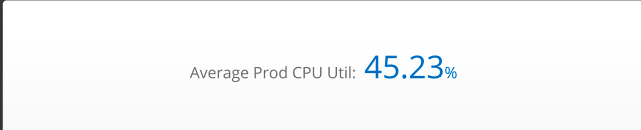
ゲージタイル
ゲージタイルは、クエリの各シリーズの特定の時点で単一の値を提供します。各ゲージには、特定のスケール(ほとんどの場合0〜100%)に対するメトリックの値を示すビジュアルが付属しています。しきい値を設定して、メトリックが特定の値に達したときにグラフの色を変更できます。
推奨される指標: ゲージメトリック、例: CPU、メモリ、ディスク
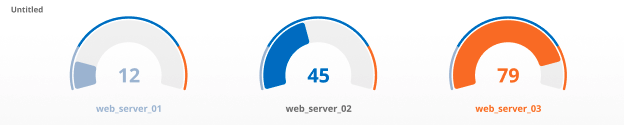
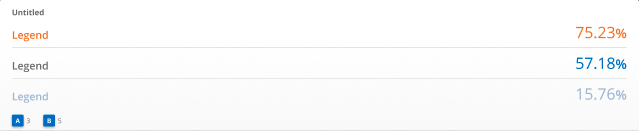
リストタイル
リストタイルには、クエリによって返されるシリーズごとに1つのメトリック値が表示されます。リストは一般的に topk また ボトムク クエリの最も極端なメトリック値を返すPromQLの演算子。
推奨される指標: ゲージメトリック、例: CPU、メモリ、ディスク
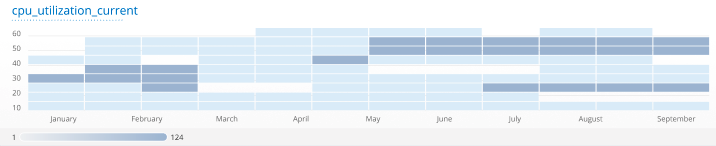
ヒートマップタイル
ヒートマップタイルは、色分けのシステムを使用して、時間の経過とともに同様のメトリック値を共有するホスト、リソース、およびアプリケーションの数を表すデータのグラフィカル表現を提供します。ヒートマップ上の各長方形は、特定の時間におけるメトリック値の範囲を表します。長方形の密度は、特定の時間(x軸)で特定の範囲(y軸)内にメトリック値を持つホストまたはリソースの数を示します。ヒートマップは、グループの傾向を表示したり、外れ値を見つけたりするのに役立ちます。このため、値の分布が広いメトリックを表示する場合は、ヒートマップタイルを使用することをお勧めします。
推奨される指標: ゲージまたはヒストグラムベースのメトリック、例:可用性、使用率、または容量のメトリック
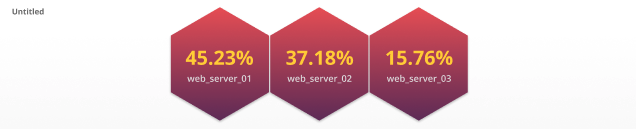
ハニカムタイル
ハニカムチャートは、DevOpsの世界で非常に人気が高まっています。このタイルは、ITインフラストラクチャの全体像を提供すると同時に、重要な詳細を提供します。ハニカムチャートは個々の六角形で構成されており、各六角形は特定のホストまたはリソースを表しています。これらの六角形は、タグ/属性に基づいてグループ化して、チャート要素の論理的な編成を提供できます。各六角形は、定義されたしきい値に達したときに色を変更することにより、対応するメトリック値も反映します。ハニカムチャートは、そのメトリックの値に基づいて各六角形のサイズを変えることにより、追加のメトリックを組み込むこともできます。
推奨される指標: ゲージ、ヒストグラム、またはカウンターメトリック
締めくくりのヒント
タイルに最適な視覚化オプションを選択したら、ダッシュボードが重要な洞察を実際に推進できるようにするために留意すべき点がいくつかあります。目標は、ITインフラストラクチャを一目で理解することです。そのため、ここで組織や設計などが重要になります。
- タイルの位置/順序: ダッシュボードの各タイルは論理的な順序で配置する必要があります。通常、ダッシュボードの下部に移動すると、重要な高レベルの統計情報が上部に表示され、より深く、より詳細なメトリックに移動します。利害関係者は、詳細に時間をかけずに、システムのパフォーマンスを理解できるようになります。
- デザイン(配色/テーマ): 指標はダッシュボードの肉とジャガイモかもしれませんが、デザインも重要な役割を果たします。見た目に美しいカラーパレットとテーマを選択すると、ダッシュボードの利用者がデータを簡単に消化して理解するのに役立ちます。
次のステップ: