

IT OpsとDevOpsの人々は指標によって生きていますが、すべての指標が同じというわけではありません。最近では、意味のあるサービスレベルインジケーター(SLI)を設定して達成します。これは、サービスレベル目標に変換されます。 (SLO)は、多くのITプロフェッショナルにとって望ましいターゲットです。 意味のあるSLOは、問題の根本原因からチームの注意をそらす可能性のある任意のメトリックとは対照的に、実際のユーザーエクスペリエンスと密接な関係があります。
SLOの一般的な例は次のとおりです。
- Webページの読み込み時間の99.99%は、250ミリ秒未満で完了します。
- HTTPリクエストの99%が成功します。
- Webページ(アプリケーション)は99.99%利用可能になります
これらのメトリックから、もう1つの重要なSLOであるエラーバジェットを計算できます。 SLOで、Webページの読み込み時間の99.99%が250ミリ秒未満で完了する場合、その範囲外、つまり250ミリ秒を超える読み込み時間の0.1%を許容できます。 SLOを設定した最終的な結果は、エンドユーザーまたは顧客との合意(公式または非公式)です。これは、SLAまたはサービスレベルアグリーメントと呼ばれることがよくあります。 SLAは通常、クレジットされた使用、割引された月、または潜在的に契約の終了など、満たされない場合に影響を及ぼします。
As Googleはそれを定義します:「SLOは、サービスの顧客に目標レベルの信頼性を設定します。このしきい値を超えると、ほとんどすべてのユーザーがサービスに満足するはずです(それ以外の場合はサービスのユーティリティに満足していると仮定します)。このしきい値を下回ると、ユーザーは不平を言い始めたり、サービスの使用をやめたりする可能性があります。」私たちは皆、幸せなユーザーメトリックを望んでいますが、それはとらえどころのないものになる可能性があります。
より良いSLO
残念ながら、これらのSLOを達成するのは難しい場合があります。 SLOは、SLOを構成するメトリックから導出されるため、次のものが必要です。インフラストラクチャの監視 適切な指標を取り込むことができるソフトウェア。 多くの組織はping(ICMP)に依存しています。これは、サービスレベルインジケーターを定義するための事実上の標準であり、通常、可用性に関するSLOに変換されます。残念ながら、pingはやや制限された指標です。これは、リソースがオンライン(「ping可能」)であることを示しますが、必ずしもビジネスへの影響を測定するわけではなく、サービスが実際に意図したとおりに実行されているかどうかを示します。 はい、可用性は常に重要ですが、これを超えると、さらに多くのことがあります。
これらは、ビジネス価値に関連する詳細な洞察を提供する種類のSLOです。
- Webサイトの読み込みは、ユーザーが戻るのに十分な速さですか、それとも遅すぎて、タスクの実行や注文に必要な情報を見つける前に押しのけてしまいますか?
- Apacheアプリサーバーは実際に400エラーを生成せずにクライアントリクエストを処理できますか?
どちらの場合も、ターゲットサービスは通常「ping可能」ですが、ビジネスまたはエンドユーザーにとって有益な方法で指定されたタスクを実行することはできません。
In OpsRampの秋の製品アップデート、意味のあるSLOを簡単に実現できるようにし、ユーザーがダッシュボードを作成する方法の柔軟性を高めました。さまざまなクラウドおよびクラウドネイティブサービスの標準のキュレートされたダッシュボードは、OpsRampのオンボーディングプロセス中に自動的に作成されますが、ITプロフェッショナルはオープンソースのクエリ言語を使用できるようになりました PromQL 非常に柔軟な視覚化を使用して、任意の数のディメンションにわたってメトリックを表示するカスタムダッシュボードタイルを作成します。 ユーザーは、タグに基づいてメトリックをクエリおよびフィルタリングできるようになり、OpsRampのメトリックカーディナリティが大幅に向上します。
はい、可用性は常に重要ですが、これを超えると、さらに多くのことがあります。
OpsRampでPromQLを使用すると、たとえば、次のように表示できます。
- 400エラーの割合とは対照的に、すべてのアプリサーバーで受信した残りのクライアントリクエストの平均。これにより、ユーザーはサービスの状態と、サービスが期待どおりに機能しているか、SLOで定義されているかを高レベルで理解できます。
これを表現するPromQLは次のようになります。
クエリA:
sum(kube_rest_client_requests {instance =〜 "。* 40。*"})/ sum(kube_api_rest_client_requests_total)ノート: 正規表現を利用して、リクエストタイプを「40」を含むものに絞り込みます。この正規表現は、500サーバー側エラーなどの他のエラータイプをフィルタリングするように変更できます。
クエリB:
avg(sum(sum_over_time(kube_rest_client_requests [5m])))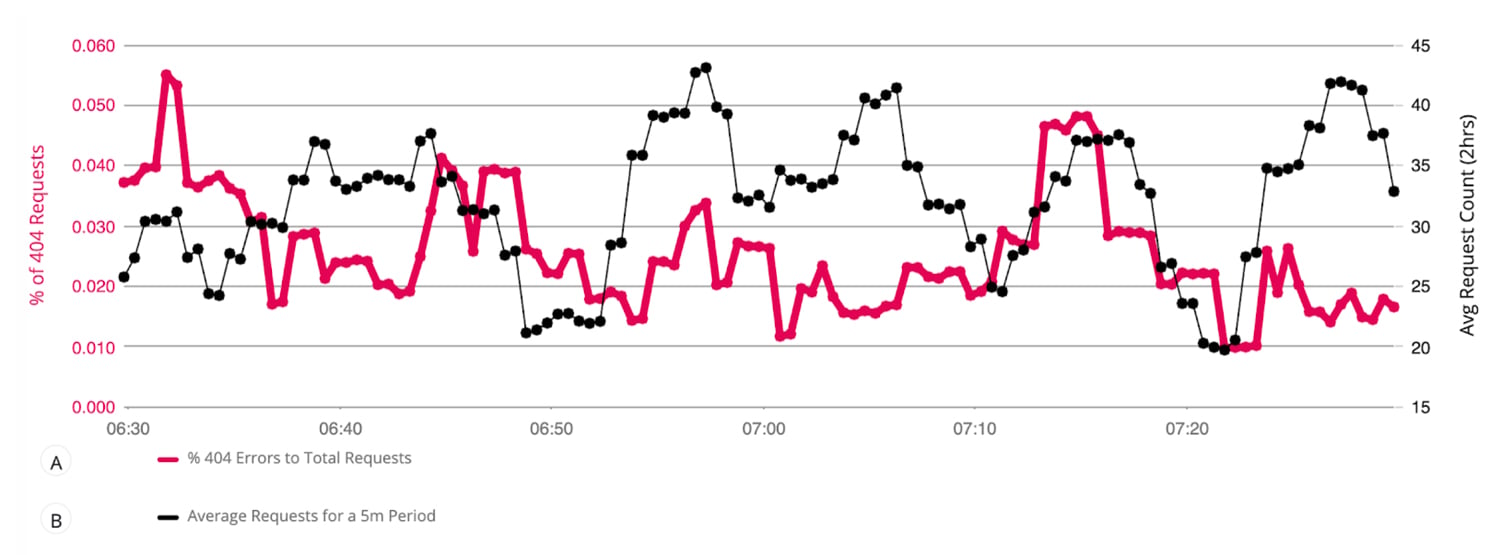
- Kubernetesホストによって処理されるHTTPリクエストのレイテンシの.95パーセンタイル。これにより、ホスト全体でのリクエストレイテンシの上限についての洞察が得られ、ユーザーは一定期間のスパイクまたはドロップを見つけることができます。これを表現するPromQLは次のようになります。
これを表現するPromQLは次のようになります。
クエリA:
分位数(0.95、(ホスト)による合計(rate(kube_rest_client_latency [5m])))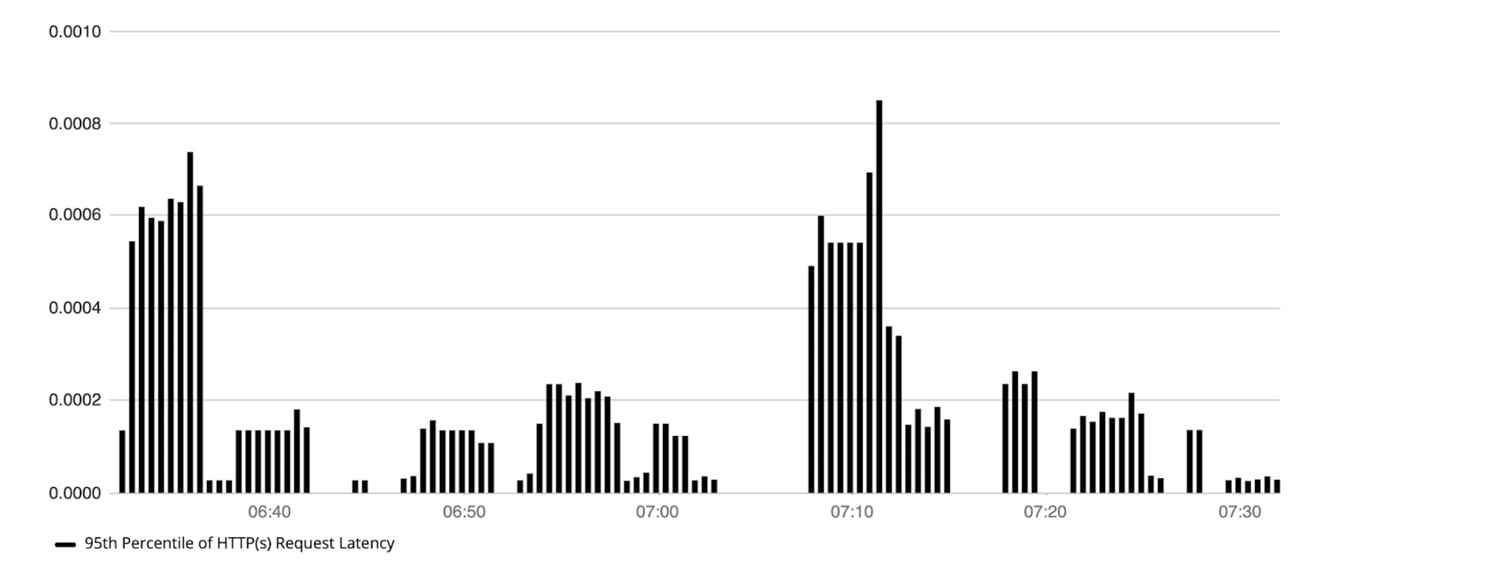
- 特定の30日間に、IPV4アドレスに「172」が含まれるホストで受信されたインバウンドパケットの数。これにより、30日間に送信されているインバウンドトラフィックの量がユーザーに通知され、スパイクやドロップなどの異常を見つけることができます。
これを表現するPromQLは次のようになります。
クエリA:
sum(sum_over_time((network_interface_traffic_in {ip =〜 "。* 172。*"} [30d])))/(1024 * 1024 * 1024)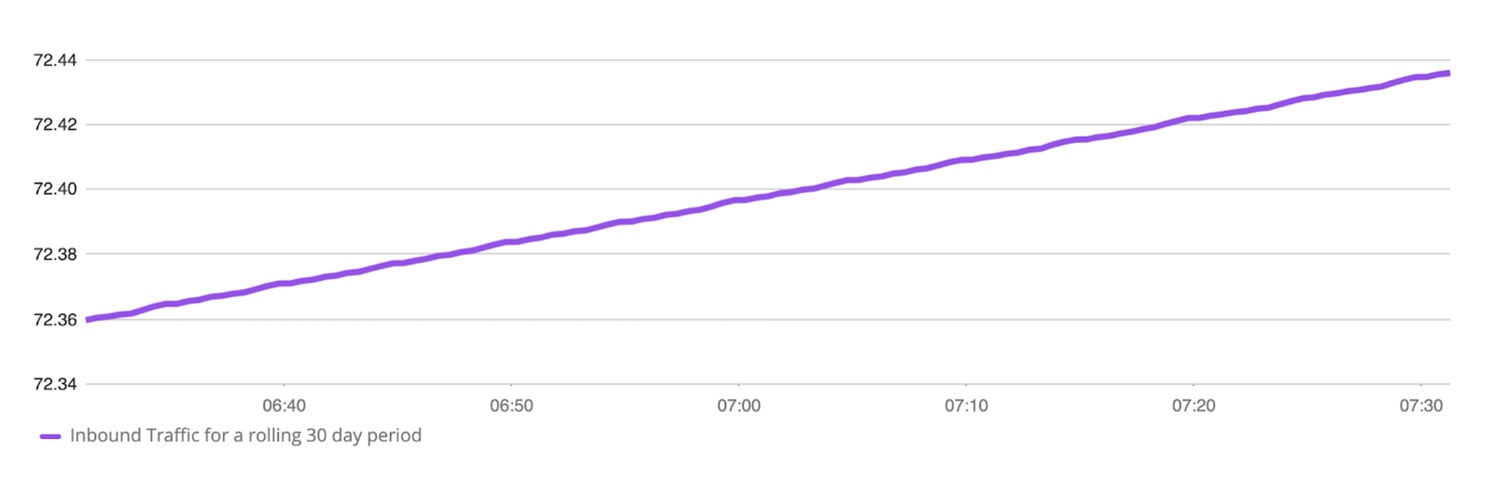
より細かく調整されたメトリックを使用した全体像の目標
より柔軟な分析は、重要なことを真に測定できることを意味します。ユーザーは、1つのリソースがダウンしていることを示すだけでなく、単一の時系列でインフラストラクチャの全体的な状態を表すクエリを実行できます。 OpsRampの秋のリリースは視覚化の先例を変え、ユーザーにメトリクスデータでより多くの洞察を推進するための鍵を提供し、キャパシティプランニングやトラブルシューティングなどの基本的なIT運用活動に関する正確な意思決定をサポートします。優れた分析はより良い結果をもたらします。私たちは、ユーザーエクスペリエンスを可能な限り優れたものにする役割を果たして喜んでいます。
次のステップ: