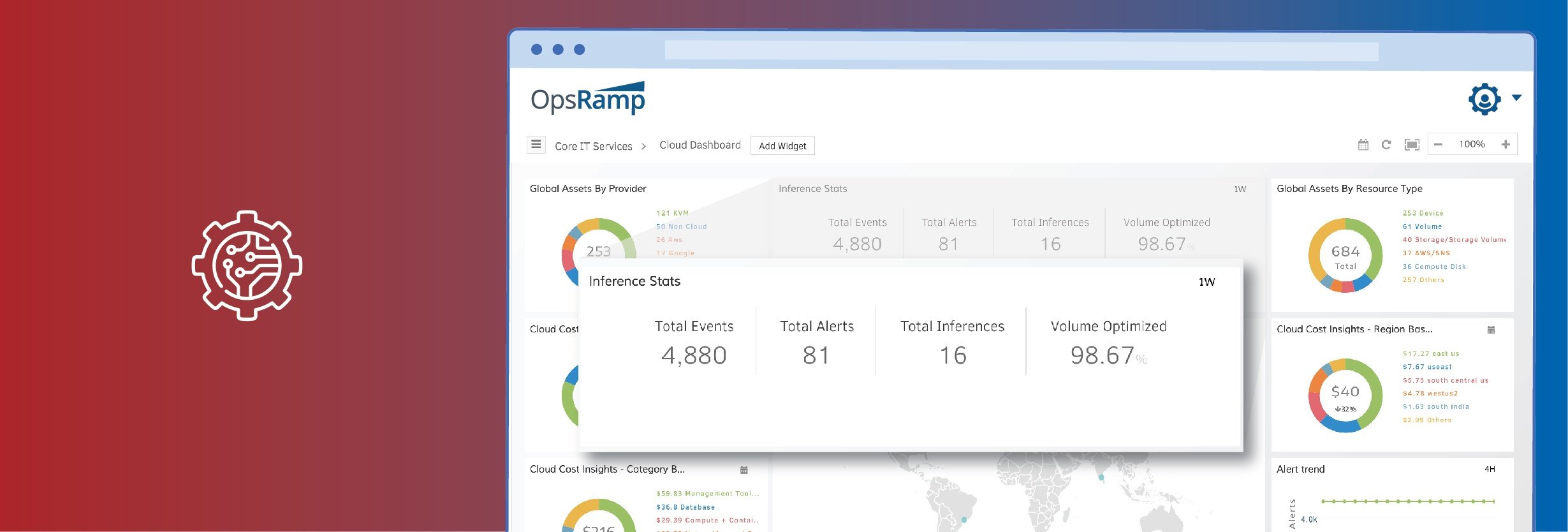


How many times does your IT operations team get lost in a sea of alerts? Can you quickly figure out the incidents that can derail your business? OpsRamp’s new Artificial Intelligence for IT Operations (AIOps) Inference Engine correlates the events generated from OpsRamp and third-party tools to help you manage endless alert floods. Let’s explore how the AIOps Inference Engine, that we launched in OpsRamp 5.0, helps you tame the complexity of modern event management.
Why AIOps? And Why OpsRamp?
AIOps and machine learning are only as effective as the data that powers the engine. And it helps when that data is contextual and complete. Existing point tools and legacy IT operations management (ITOM) suites can handle siloed operations, with products or stand-alone modules for discovery, monitoring, event correlation, alerting, service desk, and more. In contrast, OpsRamp offers a richer, deeper and more contextual view of your IT infrastructure in an integrated SaaS platform. That means you can benchmark your entire IT operations data, for a truly all-encompassing view.
OpsRamp’s extensive big data platform powers our AIOps engine, by collecting fault and performance metrics across hybrid applications and infrastructure. The engine then extracts relevant insights across operational events using statistical evidence and reasoning. OpsRamp's Inference Engine correlates specific events and groups them as an Inference. We’ll dive deeper into how this engine works in our post.
Configuring Your AIOps Inference Engine
OpsRamp offers strong capabilities for service availability and performance monitoring as part of our Unified Service Intelligence solution. OpsRamp 5.0 has taken this a step further with our new Inference Engine. Deliver dynamic and proactive insights with advanced analytical capabilities built on two different models, Topology-based correlation and Clustering-based correlation.
Topology-Based Event Correlation
Different application and infrastructure resources can comprise a business-critical IT service. When you receive a flood of alert notifications for your IT service, you need to understand what’s really happening across your hybrid workloads. Here are a few scenarios to illustrate this point:
- A bare-metal hypervisor (VMware ESXi) hosts different guest machines that run several applications. When the ESXi hypervisor goes down, it impacts the guest hosts, leading to application outages.
- Multiple switches in a data center connect to a network access switch. When the access switch breaks down due to an appliance malfunction, all the downstream switches are also affected.
- A distributed cloud application has a three-tier architecture (app, middleware, and network). When there's an impact at one of these architectural layers, app performance gets degraded. But which layer is actually causing the issue?
OpsRamp’s topology-based event correlation helps you visualize the upstream and downstream resources that comprise an IT service. You can correlate alerts using a common set of interrelated metrics for impacted resources. When you view an event stream for dependent resources, the Inference Engine correlates them based on pre-defined conditions and groups them as an inference.
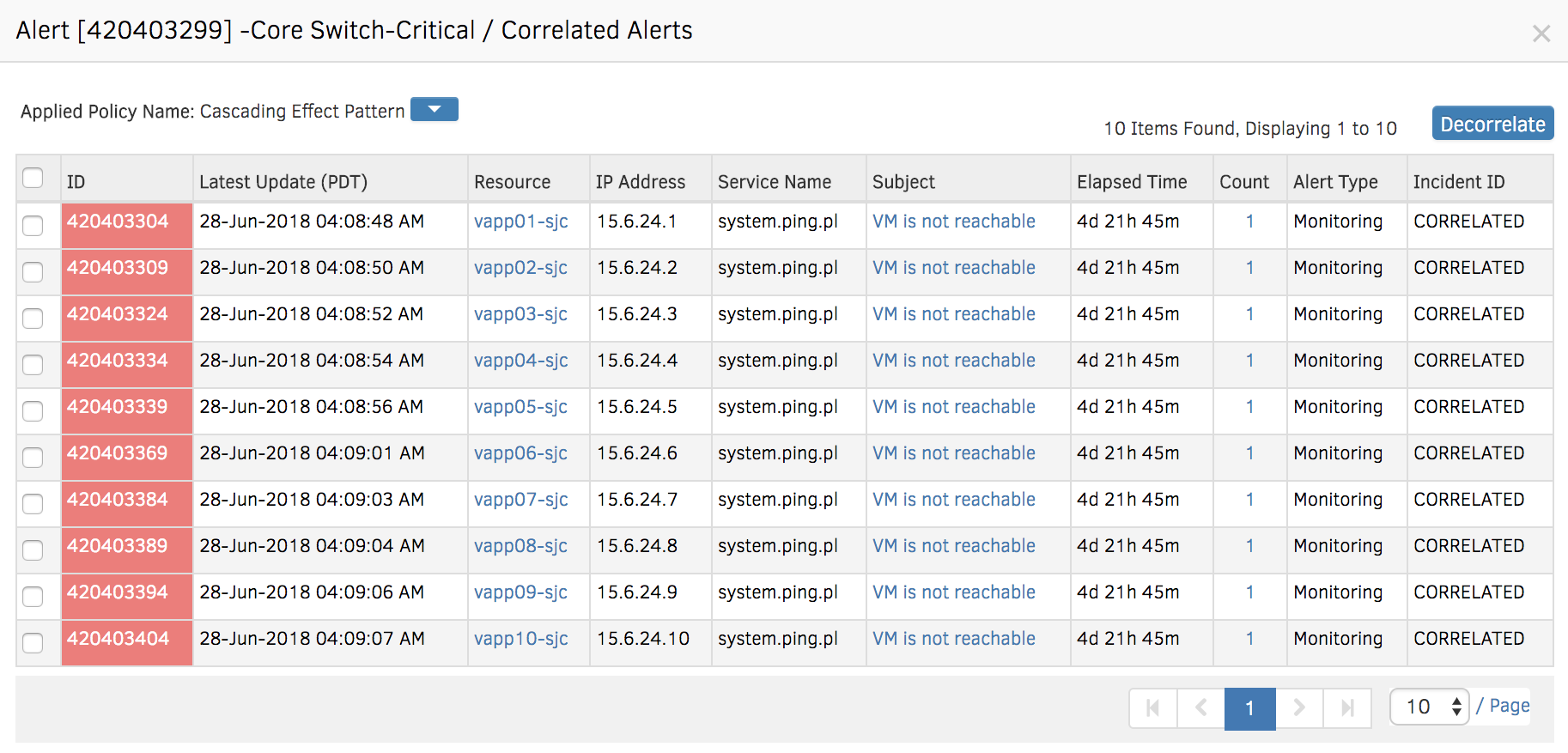 Figure 1 - Group related alerts for an event using topology-based event correlation.
Figure 1 - Group related alerts for an event using topology-based event correlation.
Clustering-Based Event Correlation
How do you keep track of the topology of a modern service and correlate events for it? With on-demand infrastructure, it is not easy keeping a handle of infrastructure dependencies for your different services. That’s why we’ve introduced clustering-based event correlation so that you can create rules to correlate events based on their attributes.
Events coming into your monitoring system carry a lot of information, including hostname, the alert subject, IP address, severity, and metrics. Clustering-based correlation uses similar attributes across events and correlates them into an inference. IT teams can analyze inferences to promptly troubleshoot and remediate an outage.
Clustering For Hybrid Workloads. Resources that support hybrid workloads are highly dynamic and scalable. The AIOps Inference Engine extracts root cause for hybrid performance issues by applying rules on resources which have similar attributes like naming conventions, subnet of IP address, and custom attributes.
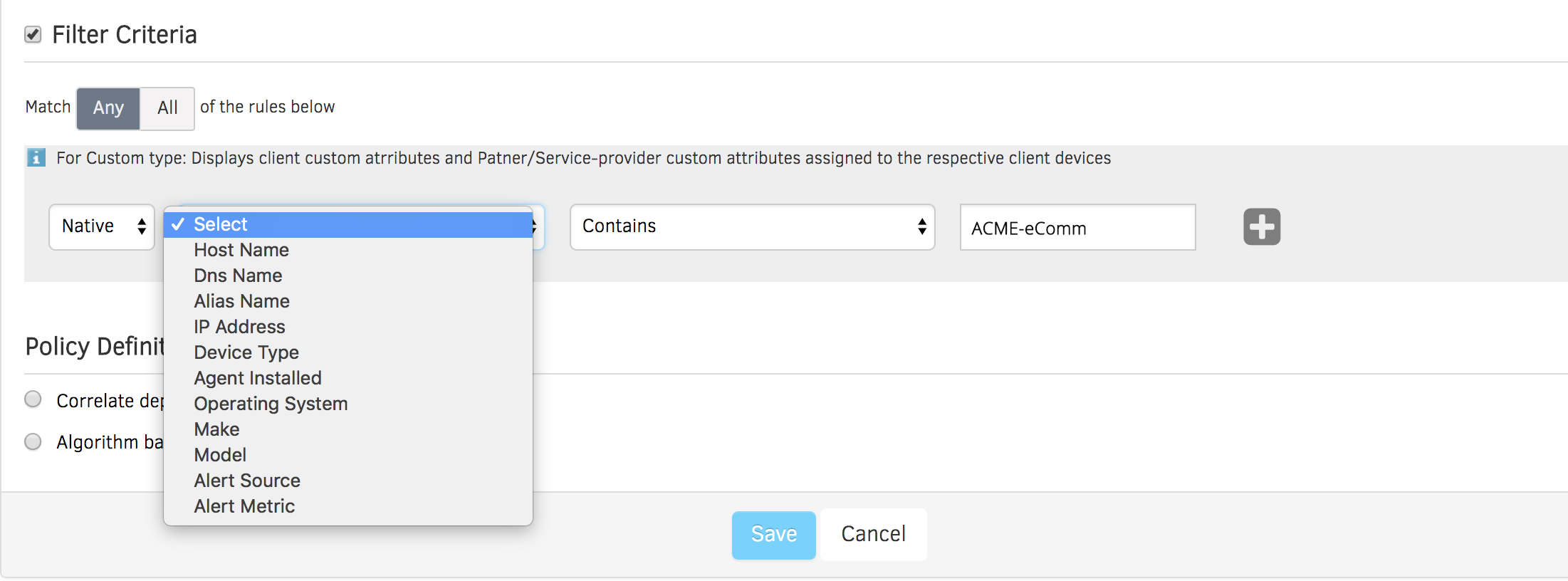
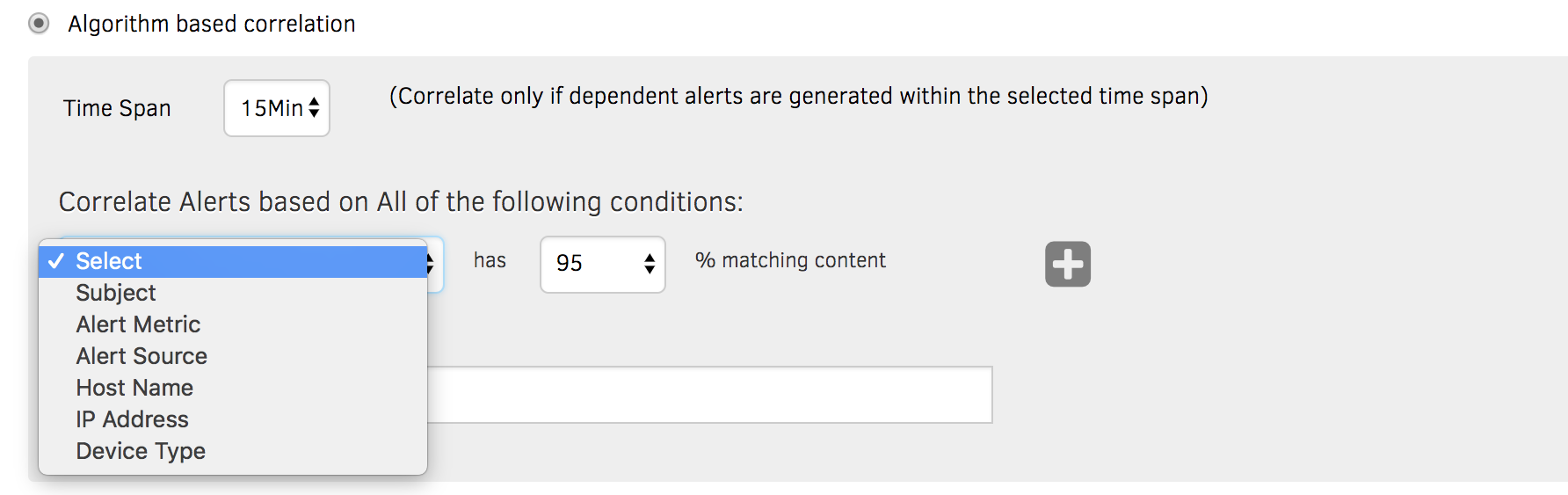 Figure 2 - The Inference Engine uses rules to correlate events across hybrid infrastructure.
Figure 2 - The Inference Engine uses rules to correlate events across hybrid infrastructure.
When you observe application degradation, it could be due to underlying infrastructure issues. Clustering-based event correlation groups related events across your infrastructure without any topology information. You can use clustering for base OS metrics, custom monitoring, log file monitoring, and process monitoring. OpsRamp provides the flexibility you need to assign the same set of rules for different workloads in your IT environment.
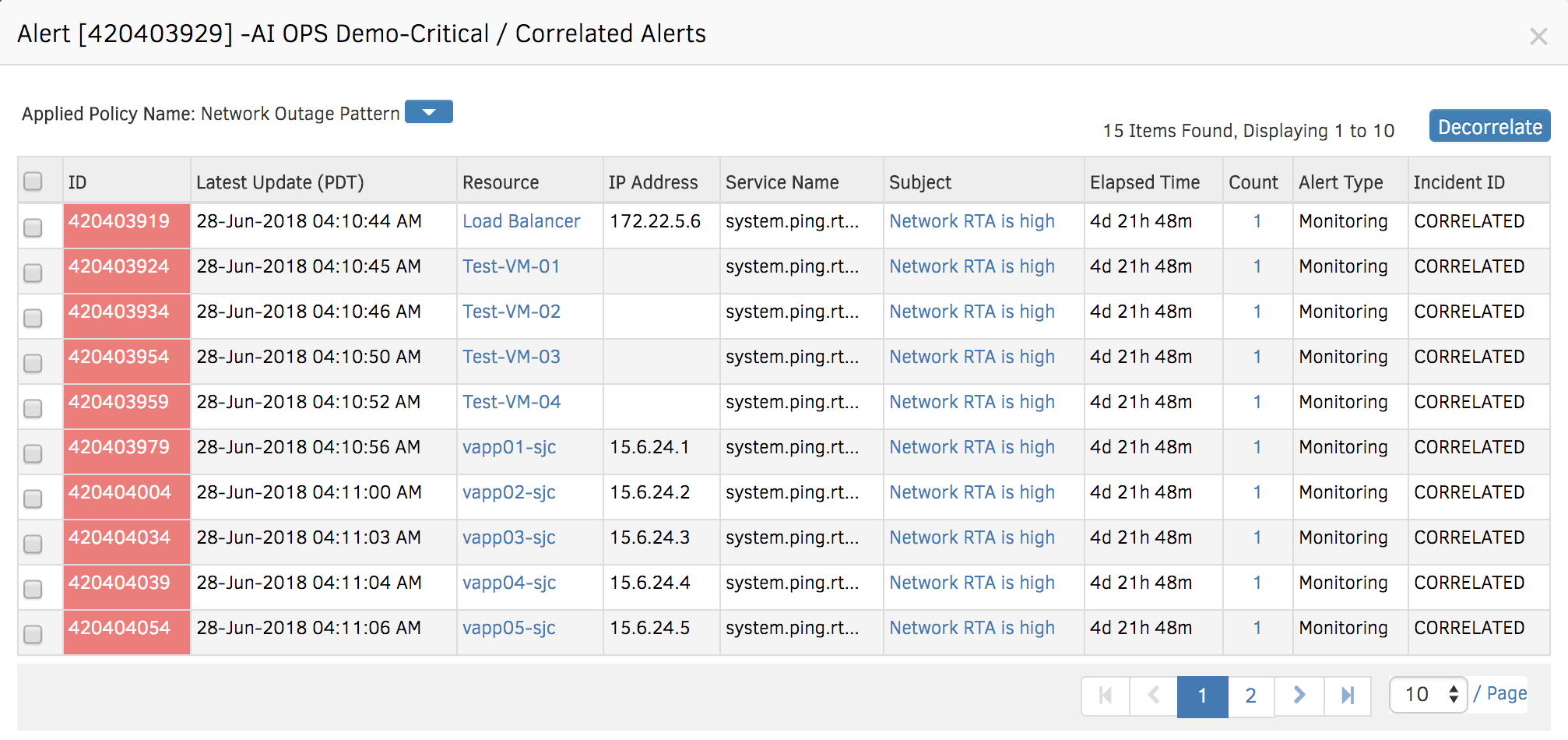 Figure 3 - Rules, correlation, and clustering. All in one place.
Figure 3 - Rules, correlation, and clustering. All in one place.
Conclusion
OpsRamp’s IT operations management platform lets you escalate AIOps inferences as a notification (email, text, voice or chat) or creates an auto-incident, all in a single place. You can also cluster events from different IT management tools by consuming them in OpsRamp and tracking them to closure.
IT teams are always looking for more efficient ways to manage the chaos of hybrid IT operations. Artificial intelligence can solve many of the problems associated with alert floods and root-cause identification. When you bring the power of AI and machine learning to OpsRamp’s Digital Operations Command Center, you gain superpowers for faster service restoration and effective operations across your enterprise.
Next Steps:
- Learn more about OpsRamp 5.0 and our AIOps Inference Engine
- Check out the OpsRamp Digital Operations Command Center
- Learn more about the Top Trends in AIOps Adoption



