

Proactive Incident Analysis, Diagnosis, and Resolution with Service-Centric AIOps
Alerts define the state of an infrastructure resource, application, or any other IP discoverable device. Organizations take action on alerts based on business impact and priority and ensure that IT service performance meets the required standards for availability, usability, and security.
The problem starts when alerts become overwhelming. In a modern enterprise with shadow IT and global teams, alert fatigue is bound to happen. IT teams start their day with a flood of alerts, and while some alerts are business-critical, most are simply downstream symptoms of a larger issue. When it comes to alert management, the trick is to both reduce the volume of alerts as well as to identify the critical root cause alerts sooner.
OpsRamp monitors hybrid applications and infrastructure using native instrumentation and also ingests third-party monitoring events for workloads not directly managed by it. Then, the OpsQ event management engine processes, analyzes, and delivers actionable inferences for faster noise reduction, predictive event correlation, and probabilistic root cause(s) identification.
Figure 1- OpsRamp’s service-centric AIOps combines data, context, and insights for faster impact analysis and proactive incident response.
Drive Multi-Level Escalations and Multi-Channel Notifications with OpsRamp’s Alert Management
Once you create an incident in OpsRamp, alert escalation policies deliver timely action on outstanding alerts by ensuring that critical alerts move up the chain of command using on-call schedules and escalation matrices. Alert escalation policies provide automated response actions for incoming alerts and help IT teams manage alerts to defined service levels. Escalation policies not only send alerts to DevOps teams via communications media of their choice (email, text, voice, and auto-incidents) but also automatically create and assign tickets based on priority.
Here’s how OpsRamp’s alert escalation policies deliver context-rich incidents to on-call teams, automate incident routing, and integrate incident status with external ticketing tools:
-
Be the First to Know With Alerts Notification Engine. Hybrid and multi-cloud resources generate a huge volume of IT events across commercial software, open source systems, and custom workloads. During critical outages, application owners, IT infrastructure, and DevOps teams work together to quickly restore affected services. Using shift rosters, OpsRamp’s alerts notification engine dispatches alerts to on-call staff with the right expertise to troubleshoot and repair impacted IT services. Notification channel configurations for SMS and Voice gateways come pre-built in the OpsRamp platform so that IT teams can simply flag and receive the right set of alerts for resolution.
Incident teams can customize alert tokens (to define policy name, alert attributes, and channel preferences) in an alert notification so that users have the right situational context to immediately act on an issue. Teams can also tag alerts with relevant knowledge articles for information on operational procedures and troubleshooting tips for faster turnaround times for frequently occurring issues.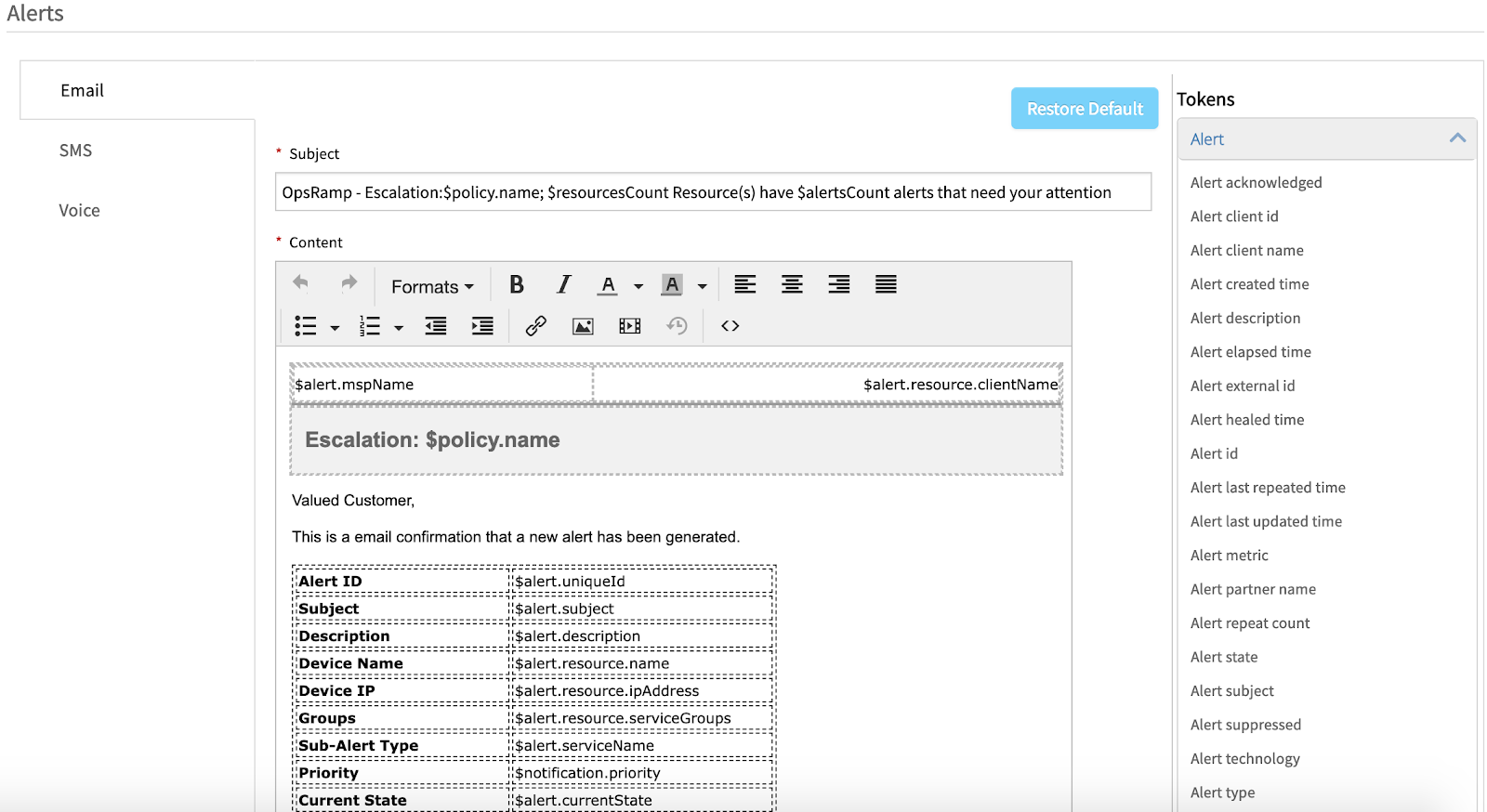
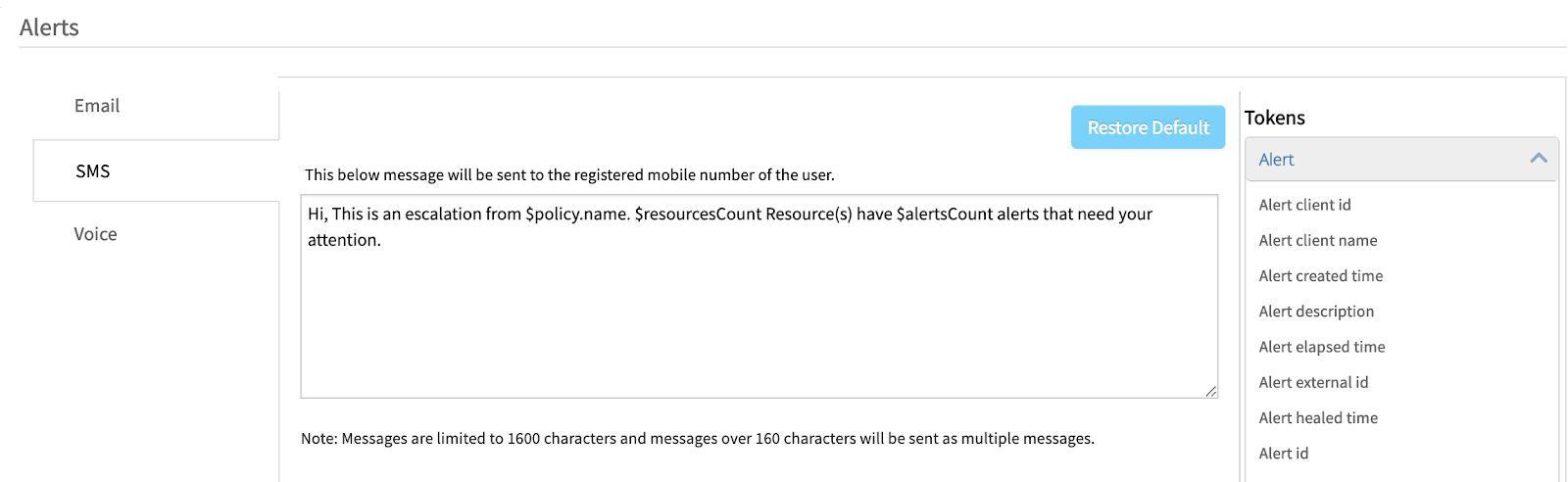
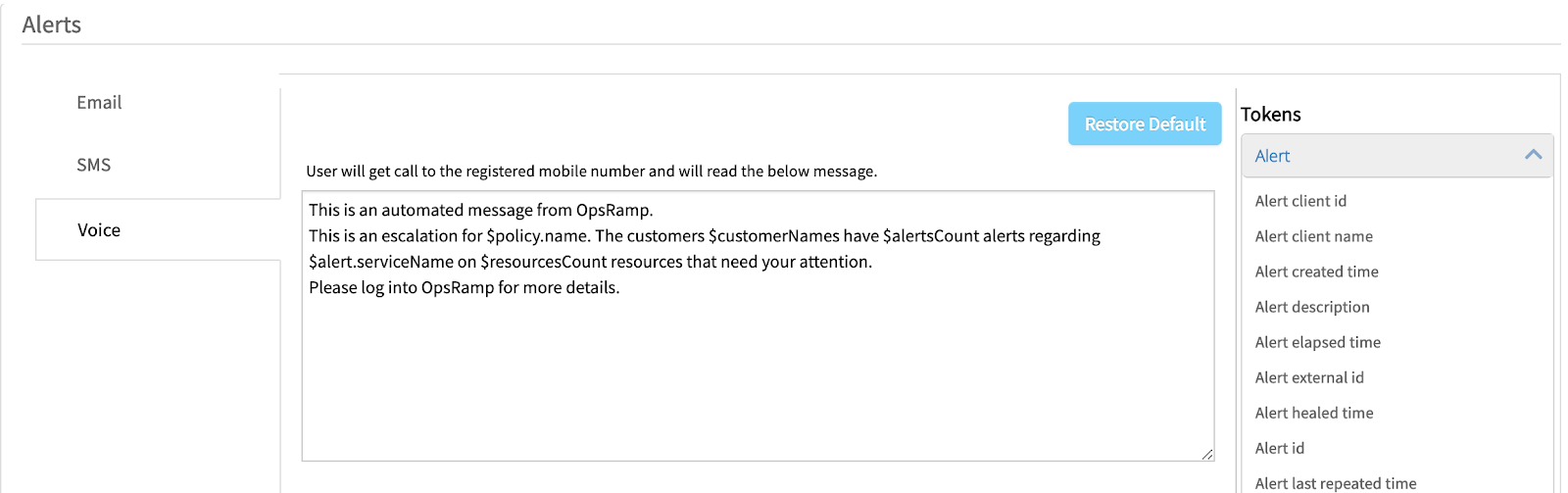
Figure 2 - Configure alert properties and alert escalation conditions in OpsRamp for email, text, and voice notification templates. -
Reduce Mean-Time-To-Resolution With Auto-Incident Creation and Routing. OpsRamp’s service-centric AIOps ensures rapid incident remediation with faster problem isolation, accurate root cause diagnosis, and actionable alerting. IT teams can access dynamic incident context in OpsRamp so that they can reduce downtime for service degradations with clear operational visibility. OpsRamp’s integrations with popular service desk tools ensure that you can create, refresh, and close incidents in OpsRamp and have that incident details automatically show up in ServiceNow ITSM.
The Winter 2019 release introduces new capabilities for auto-incident management. OpsRamp’s machine learning-powered escalation policies can proactively learn from existing incident data to assign incident priority based on business impact, urgency, category, sub-category, priority, and assignee groups.
With the auto-incident capability, customers no longer have to manually create and route incidents anymore. Organizations can train the OpsRamp platform to assign incidents to appropriate teams based on resource groups, business services, or specific metrics. Our future roadmap is to have continuous learning capabilities by leveraging incident data in OpsRamp for automatic incident placement and ownership.
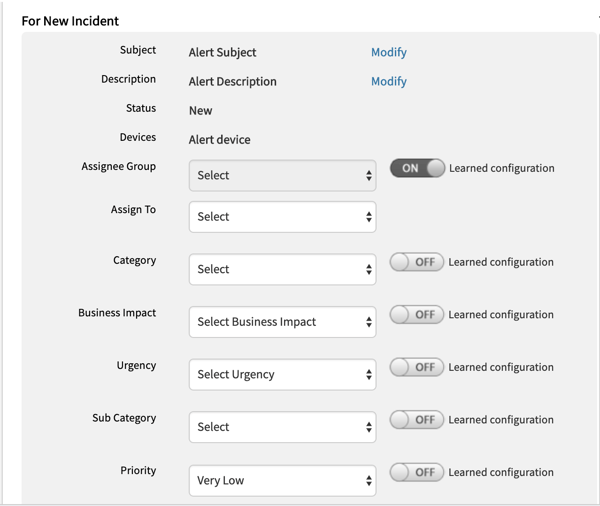
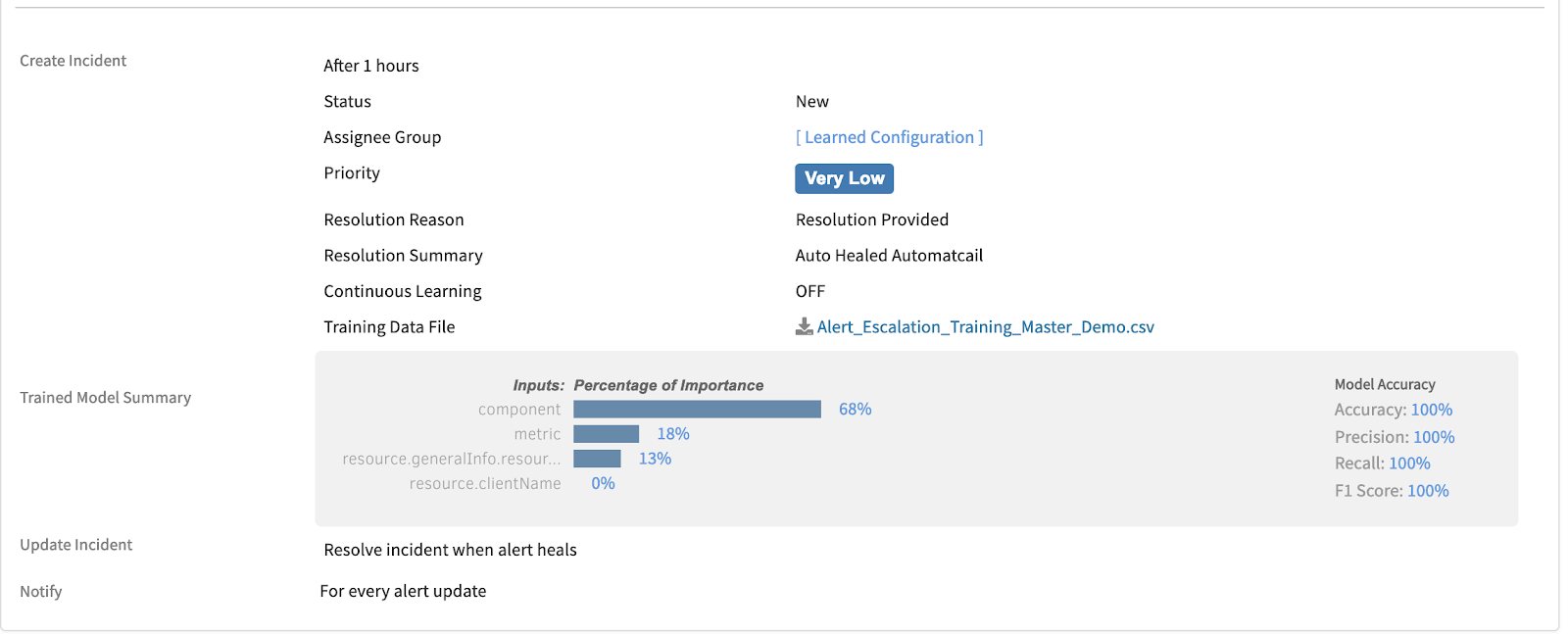
Figure 3 - Drive rapid incident response by quickly creating, classifying, and assigning incidents.
Next Steps:
- Learn more about Intelligent Incident Management.
- Read 451 Research’s report on how OpsRamp is driving innovation with machine-learning powered AIOps.
- Schedule a custom demo with an OpsRamp solution expert.



