

Why IT Outages Are The New Normal
IT outages are becoming the world’s most frequent natural disasters. An unexpected technology glitch might prevent you from catching a flight, ordering dinner for your family, or selling your stock portfolio at the right time. Here are some recent IT outages that have caused reputational damages, financial losses, and customer churn at major organizations this year:
-
A failed IT upgrade in April caused a series of outages at UK's TSB Bank, preventing customers from accessing their online bank accounts for several weeks. The outages have cost the bank more than $200 million, affected 2 million customers, and forced the CEO, Paul Pester, to finally resign in September.
-
The Internal Revenue Service (IRS) suffered a major system outage on the last day of tax filing (April 17) due to an unpatched firmware bug. Thanks to the eleven-hour outage, five million taxpayers were unable to file their taxes. The IRS extended the deadline by another day to help taxpayers file their returns in time.
-
Gatwick Airport, the UK’s second busiest airport, experienced an embarrassing outage in August when it had to resort to whiteboards for displaying flight times and gate numbers. The airport’s flight information display systems stopped functioning for nearly eight hours due to a damaged fiber optic cable. The disruption led to passengers second-guessing their flight location, leading to missed flights during a holiday season.
AIOps To The Rescue
While IT outages introduce major short-term pains, analyst firm IDC has found that 50% of organizations will not survive a major tech-related disruption when it hits them. Given that the frequency of digital disruptions is only increasing every year, IT operations teams need a new approach for handling high-consequence situations. The emerging discipline of service-centric AIOps is a much-needed panacea for detecting patterns, identifying anomalies, and making sense of events across hybrid infrastructure.
AIOps leverages a broad set of technology approaches, including machine learning, network science, combinatorial optimization and other computational approaches for solving everyday IT operational problems at scale. Enterprises can address a wide variety of IT management activities with AIOps, such as intelligent alerting, alert correlation, alert escalation, auto-remediation, root cause(s) analysis and capacity optimization.
Determine Cause And Effect Better With OpsQ
This week, we announced OpsRamp OpsQ, an intelligent event management, alert correlation, and remediation solution for service-centric AIOps. OpsQ delivers observation, analysis, and automation for ever-growing amounts of performance data using machine learning algorithms.
So, how does OpsQ actually manage your IT events at scale? OpsQ delivers event management superpowers for modern IT teams with faster incident detection and response using:
-
Alert Generation. Gain holistic and cross-domain IT visibility with the ability to consolidate native and third-party events.
-
Ingestion. Extract relevant insights and predict future outcomes by normalizing and analyzing vast quantities of IT event data.
-
Inferencing. Detect unexpected patterns by de-duplicating and correlating multiple events that are fundamentally related to the same common cause.
-
First Response. Drive automatic remediation by suppressing alerts and initiating runbooks for remedying repetitive incidents.
-
Escalation. Restore services faster with tailored notifications to your on-call staff and automatically create incidents for high-priority issues.
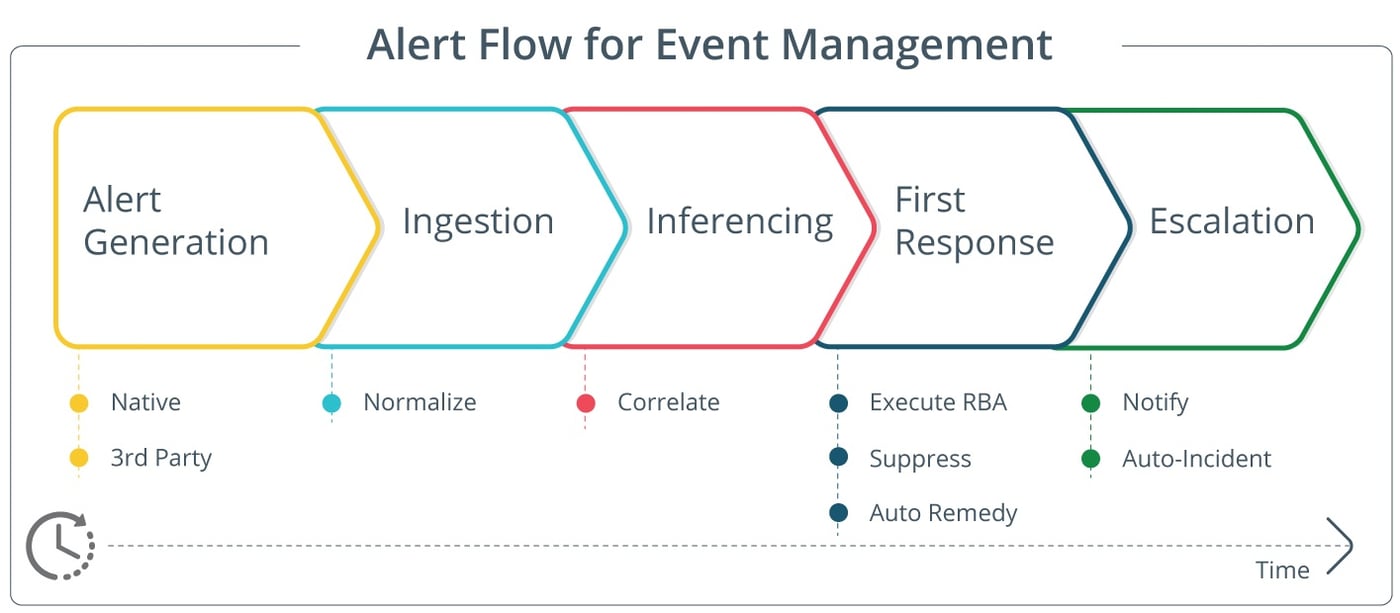
Figure 1 - OpsQ’s five-step approach for IT event management and analysis.
Inference Models for Sharper Intuition and Accelerated Decision Making
OpsQ offers three different inference models that you can apply to your IT application and infrastructure stack. Inference models offer the ability to set filter criteria and apply an analytical model to a particular type of IT resource. OpsQ’s inference models are easy to set up and configure so that you’ll be able to analyze your incoming alert streams in no time:
-
Topology. Understand the relationships between IT services and underlying infrastructure. Identify the root cause alerts for an incident with the right situational context and impact analysis.
-
Clustering. Cluster events based on their attributes by analyzing similarities and correlating different alerts into one inference alert.
-
Co-occurrence. Analyze alert sequence patterns for existing alerts to correlate alerts and identify the root cause(s) for an incident.
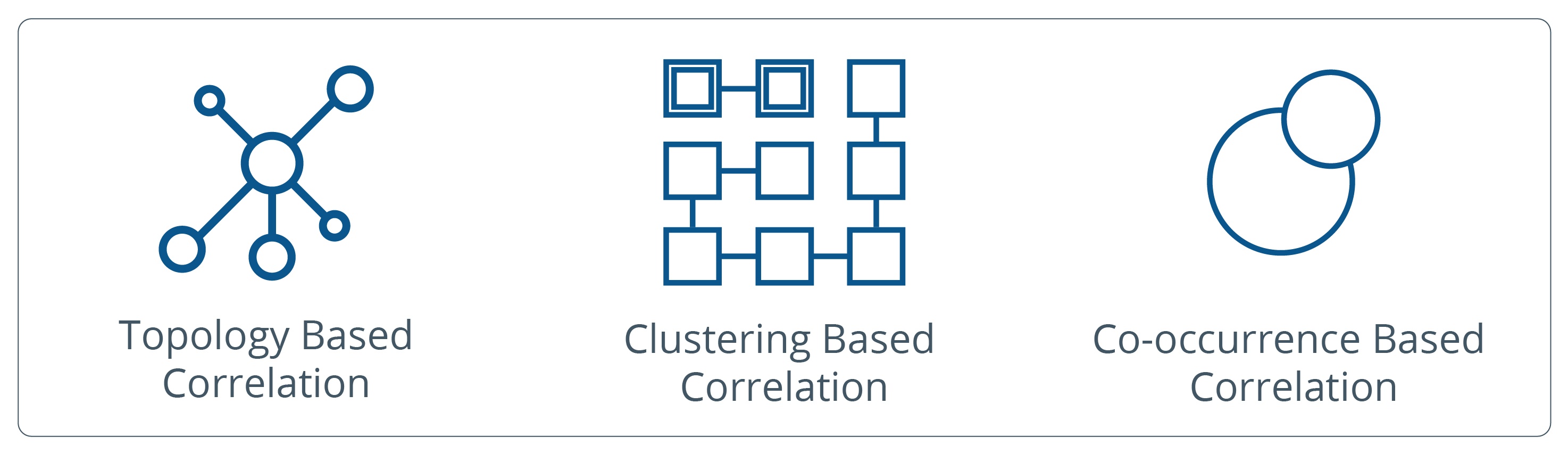
Figure 2 - Leverage statistical evidence and reasoning with OpsRamp’s three inference models.
Manage Your Incident Lifecycle With OpsQ
OpsRamp OpsQ harnesses the tremendous potential of machine learning and artificial intelligence to address the problems of technology disruptions to business operations. Enterprises will be able to enhance operational efficiencies and boost productivity for IT infrastructure management by leveraging OpsQ to reduce the human time spent per alert for:
- Business-Service Impact. Pinpoint root cause(s) by understanding interdependencies between IT services and infrastructure workloads.
- Noise Reduction. Consolidate and compress raw alerts into context-infused events so that you can better predict performance problems.
- Incident Response. Fix the problems of notification overload and chaotic incident response with proactive insights for hybrid infrastructure issues.
- Prompt Resolution. Route relevant alerts to relevant staff using effective communication channels (email, voice, SMS, and chat) and on-call schedules.
Watch OpsQ In Action
Next Steps:
- Download our Top Trends In AIOps Adoption report.
- Check out the OpsRamp OpsQ datasheet.
- Schedule a custom demonstration with a solution consultant today.



