

NS 2020年のクラウドレポートの状態 Covid-19により、企業の60%がクラウドインフラストラクチャの使用を増やすことがわかりました。ハイブリッドインフラストラクチャの採用は、IT運用チームに新たな管理上の課題を生み出し、テクノロジー予算の縮小とスタッフのスキル不足によってさらに悪化します。ガートナーは次のように予測しています IT運用チームの40%は、2023年までにAI拡張自動化を導入する予定です 顧客の期待と変化するビジネスモデルに追いつくために。
機械学習への投資は生産性を高めることができますが、ITリーダーは、組織のプロセス、スタッフの準備状況、ツールスタックを調べて、実際の運用の価値を実現する必要があります。テクノロジーの幹部やマネージャーが変革を行う際に考慮すべきいくつかの質問があります IT運用エンタープライズデジタルトランスフォーメーションの課題に対応するには:
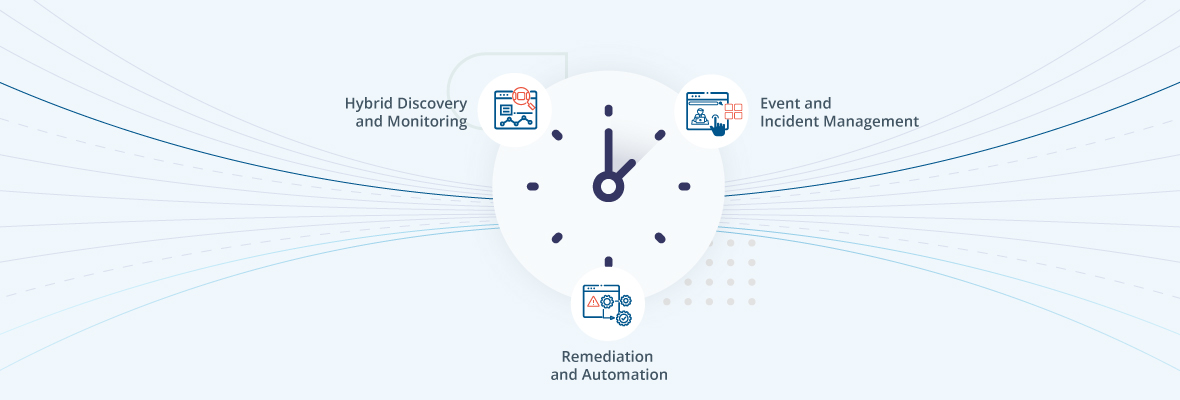
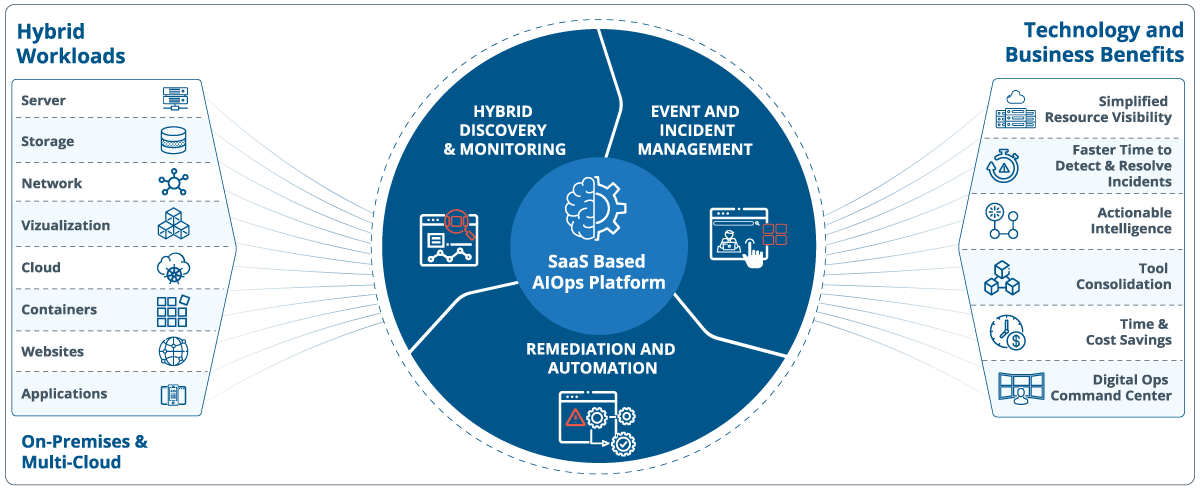
| ハイブリッドディスカバリーとモニタリング |
|
| イベントとインシデントの管理 |
|
| 修復と自動化 |
|
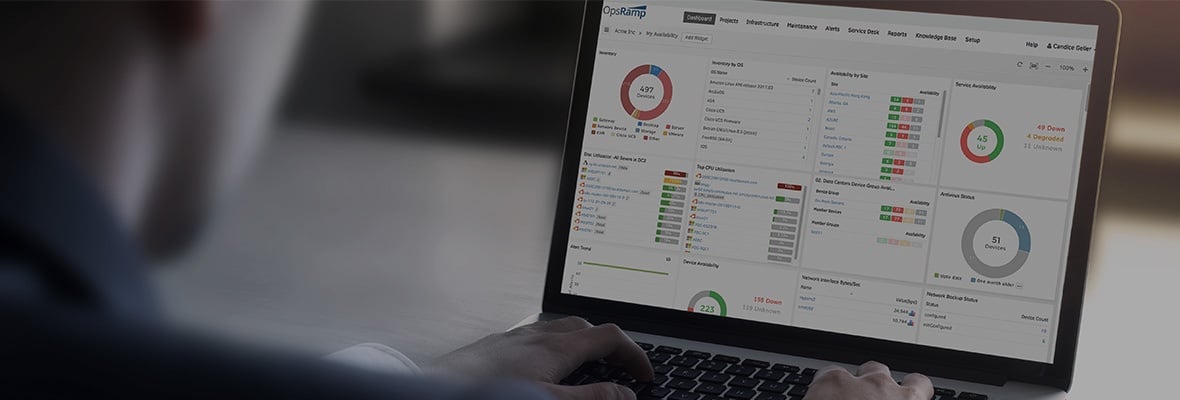
OpsRampがどのように発見から解決を可能にするか
OpsRampは、信頼できる唯一の情報源を使用してインフラストラクチャランドスケープを検出、監視、および最適化することにより、エンタープライズ運用ライフサイクルの重要な段階を自動化できます。 NSプラットホーム 3つのアプローチを使用して、適切な状況認識を提供します。 IT運用管理:
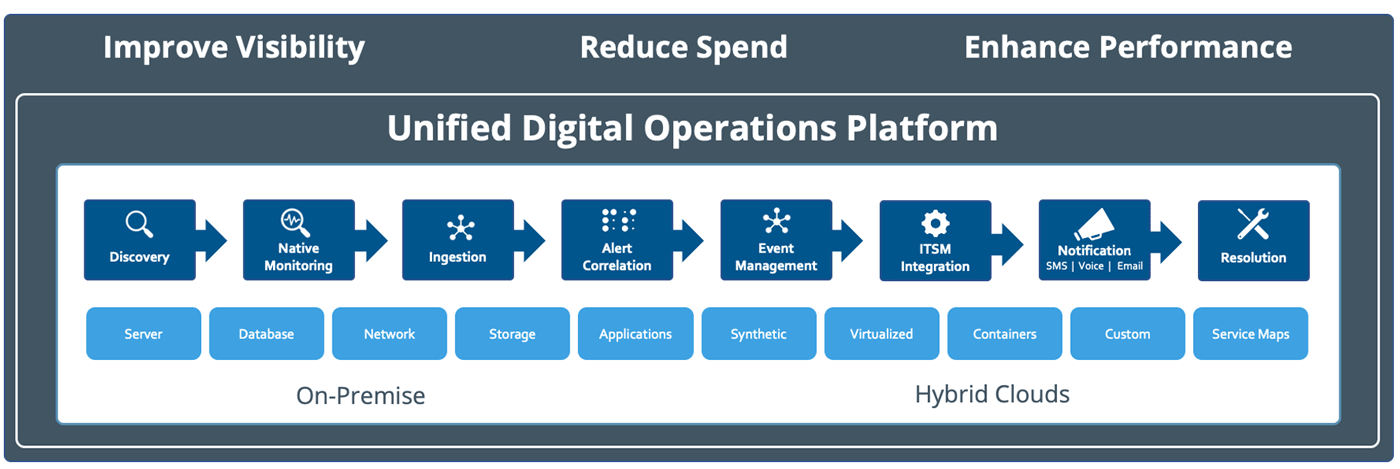 自動化されたIT運用により、ビジネスの俊敏性とより迅速なイノベーションを推進します
自動化されたIT運用により、ビジネスの俊敏性とより迅速なイノベーションを推進します
ハイブリッドディスカバリーとモニタリング さまざまな物理、仮想、マルチクラウド、およびクラウドのネイティブアプリケーションとインフラストラクチャを検出および監視することにより、システムヘルスの統一されたビューを提供します。
- 発見。OpsRampは、スケジュールされた動的な検出を使用して、レガシーおよび最新のワークロードをオンボードできます。プラットフォームは、パブリッククラウドプロバイダーからの監査ログを利用することで、新しいクラウドサービスのリアルタイム検出を開始できます。 ITオペレーターは、長期的で一時的なインフラストラクチャ全体のライブ資産インベントリビューを使用して、最近のインフラストラクチャの展開に関する洞察を得ることができます。サービスマップを使用すると、ITチームは、ミッションクリティカルなサービスの依存関係をリアルタイムで把握して、リソース障害の影響を理解できます。
- モニタリング。 OpsRampは、動的、分散、およびモジュラーインフラストラクチャの可用性とパフォーマンスを追跡するための適切な監視ポリシーを自動的に割り当てることができます。監視ポリシーは、パフォーマンスメトリックと動的なしきい値を組み合わせて、ITチームがユーザーに影響を与える前に問題を特定して解決できるようにします。すぐに使用できるダッシュボードとウィジェットは、インフラストラクチャインベントリ、サービスの可用性、および企業全体のインシデントステータスのパフォーマンストレンドを即座に可視化します。
イベントとインシデントの管理 ネイティブイベントとサードパーティイベントを分析し、イベントの重複排除、相関、抑制を使用してノイズから信号を抽出します。
- 重複排除。 OpsRampは重複排除技術を使用して、関連するイベントを組み合わせ、誤った重要でないアラームを除外します。
- 相関。機械学習アルゴリズムは、イベントパターンを分析して、同じ一般的な原因にリンクされているさまざまなイベントを相互に関連付けます。
- 抑制。 ファーストレスポンスポリシーは、季節的で反復的なアラートを抑制し、ITチームが毎日何百ものアラートを手動で分析する必要がなくなるようにします。
- エスカレーション。アラートエスカレーションポリシーは、電子メール、テキスト、音声などのさまざまな通信チャネルを介して、状況に応じた通知をオンコールチームに配信します。
修復と自動化 Runbookと自動化ワークフローを使用して、ITインシデントと日常業務への迅速な対応を可能にします。
- 自動修復。プロセスの自動化により、オペレーターは一般的な運用上の問題を特定し、人間の介入なしにそれらを修正できます。
- パッチ管理。 ITチームは、展開前にソフトウェアパッチをスキャン、承認、構成、および承認することで、セキュリティの脆弱性と戦うことができます。
- 安全なアクセス。リモートコンソールは、オペレーターがIT環境で実行できるアクションの厳密なアクセス制御を保証します。コンソールは、すべてのキーストロークアクションのセッション記録を備えた信頼性の高い監査証跡も提供します。
次のステップ: