

アプリケーションの需要を満たすためにインフラストラクチャの容量を一致させる
クラウド容量管理の最大の課題の1つは、動的なアプリケーションの要求を処理するための最も効率的な方法を見つけることです。 AWS 自動スケーリング 実際のアプリケーションの使用状況と需要に基づいて、AWSインフラストラクチャの容量を自動的に拡大および縮小します。 Auto Scalingは、EC2、ECS、Spot Fleets、DynamoDB、Aurora、AppStream 2.0、EMRなどのAWSサービスのホスト全体で利用できます。 AWS Auto Scalingを使用すると、アプリケーションを構成する特定のAmazonサービスを選択し、各リソースのスケーリングオプションを選択できるため、可用性とパフォーマンスを大規模に維持できます。
Auto Scalingリソースは、ワークロードの要求に基づいて、短時間のバーストで機能します。 Auto Scalingインスタンスの動的で一時的な性質を考えると、クラウドネイティブアプリケーションの状態を管理するための適切な洞察をどのように取得しますか? OpsRampの 監視の自動化 ディスカバリープロファイルエンジンと運用ダッシュボードを使用して、ポリシー主導の方法で自動スケーリングシナリオを処理し、適切な可視性を実現します。
AWS 自動スケーリングのポリシーベースの検出
OpsRampは、APIベースの検出プロファイルを使用してAWSインフラストラクチャとプラットフォームサービスを自動検出します。クレデンシャルセットを提供し、ポリシーを定義し、クラウド検出のスケジュールを設定すると、 AWSディスカバリープロファイル エンジンは、クラウドネイティブサービスを論理的に整理するために、クラウドリソースをサービスグループに自動的に割り当てます。
APIベースのスケジュールされた検出を呼び出すか、CloudTrailアラームを使用して、OpsRampでAWS AutoScalingインスタンスの変更を追跡できます。 OpsRampが大規模な継続的なクラウド検出を推進する方法は次のとおりです。
- 自動スケーリングワークロードのスケジュールされた検出。 OpsRampのスケジュールされた検出は、定義された間隔(分、時間、日、週、月)でAWSリソースをスキャンして、AutoScaleインスタンスへの変更を追跡します。 Discovery APIは、アベイラビリティーゾーン、作成時間、必要な容量、最大サイズと最小サイズ、AWS AutoScalingインスタンスのオープンアラートなどの関連属性をキャプチャできます。

図1-スケジュールされた検出は、AWS AutoScalingリソースへの変更を追跡するのに役立ちます。OpsRampでAWSAutoScaleインスタンスについて確認できるさまざまな指標は次のとおりです。
- GroupMinSize-AutoScalingグループの最小サイズ。
- GroupMaxSize-AutoScalingグループの最大サイズ。
- グループの希望する容量-自動スケーリング グループによって維持されているインスタンスの数。
- グループサービスインスタンス-AutoScalingグループで実行されているインスタンスの数。
- グループ保留中のインスタンス-まだサービスを提供していないインスタンスの数。
- グループスタンバイインスタンス-スタンバイ状態にあるインスタンスの数。
- グループ終了インスタンス-終了中のインスタンスの数。
図2-AWSAutoScalingインスタンスの適切な運用上の洞察を得る。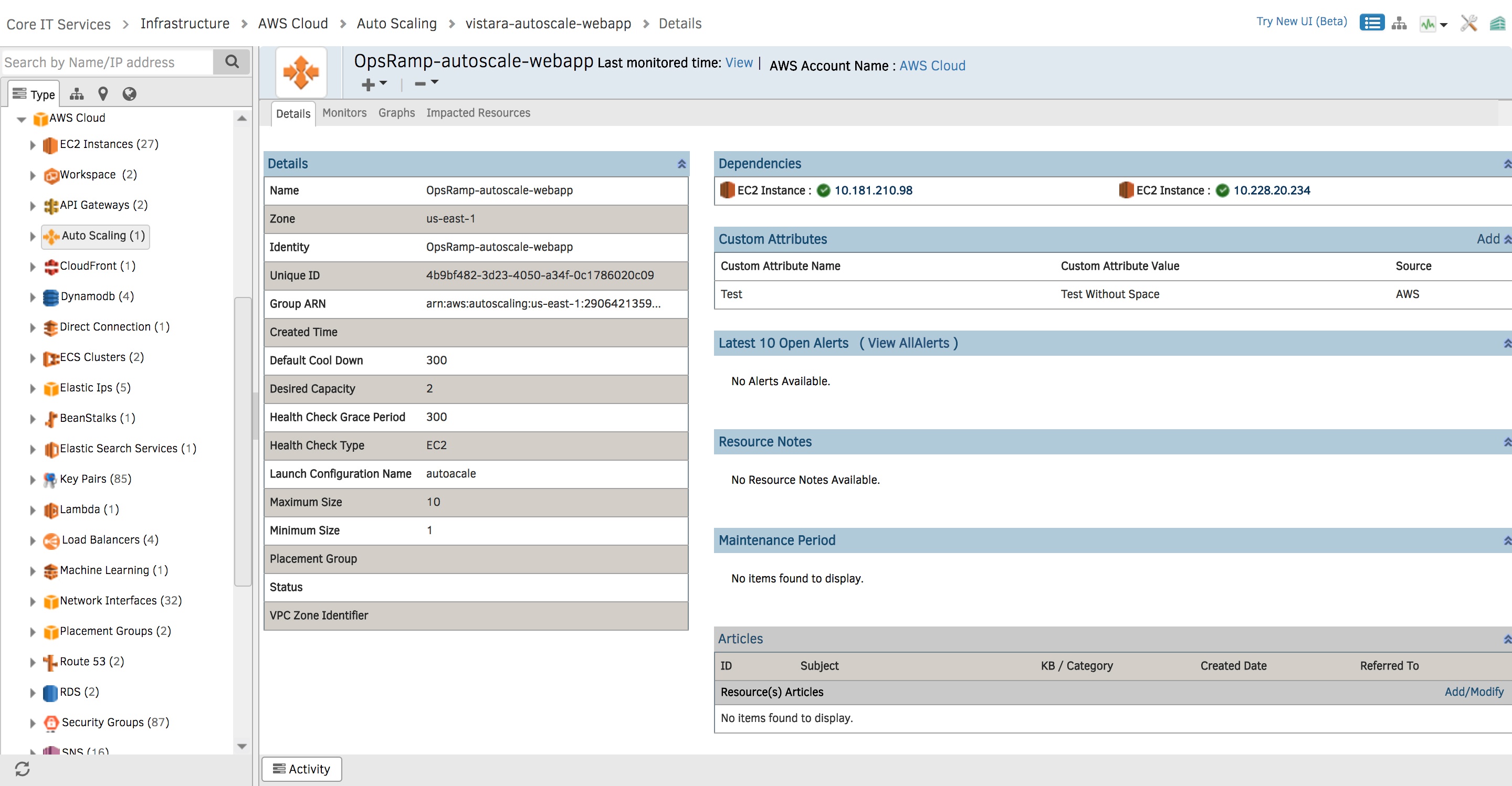
AWS AutoScalingのモニタリング指標をグラフの形式で視覚化できます。 ITチームは、特定のメトリックのしきい値を設定し、逸脱があるたびにアラートを受信することもできます。
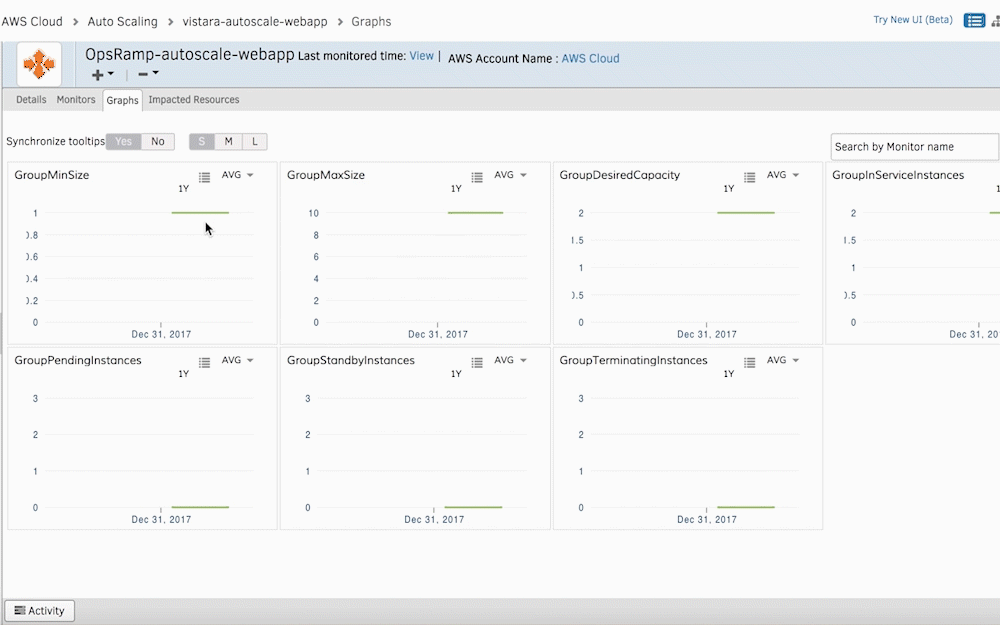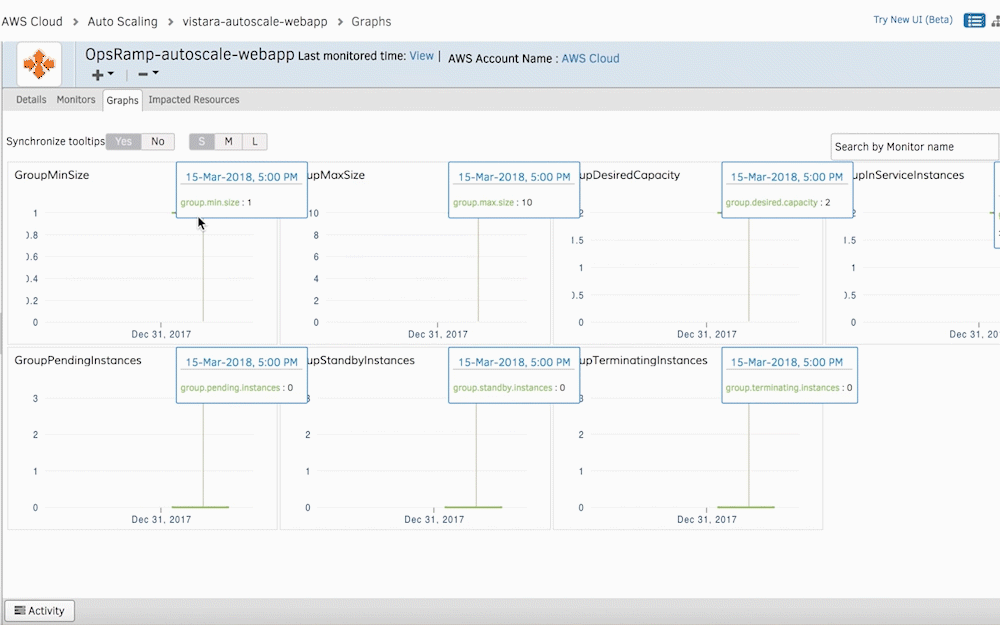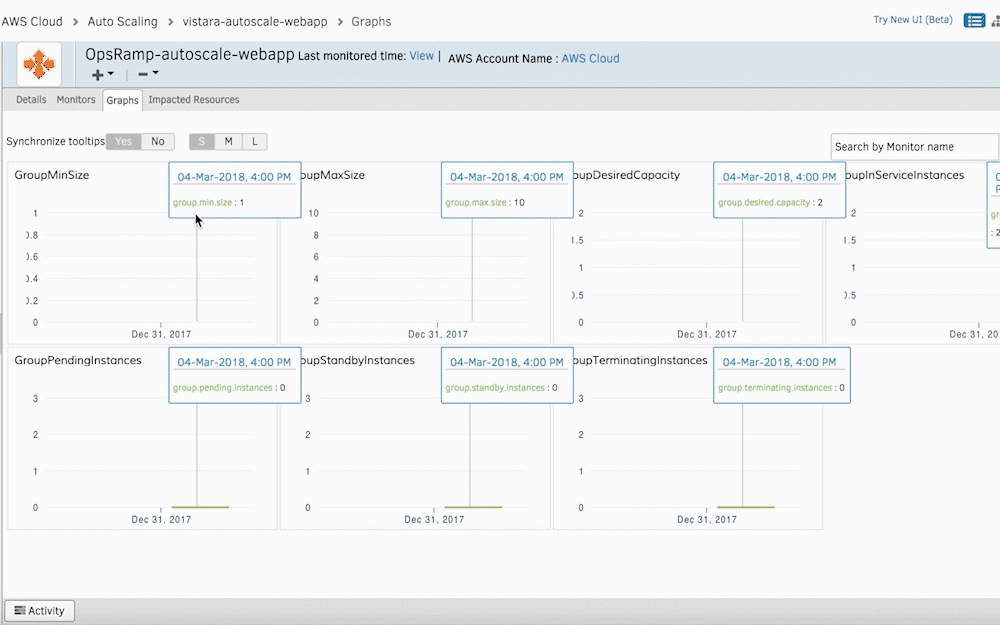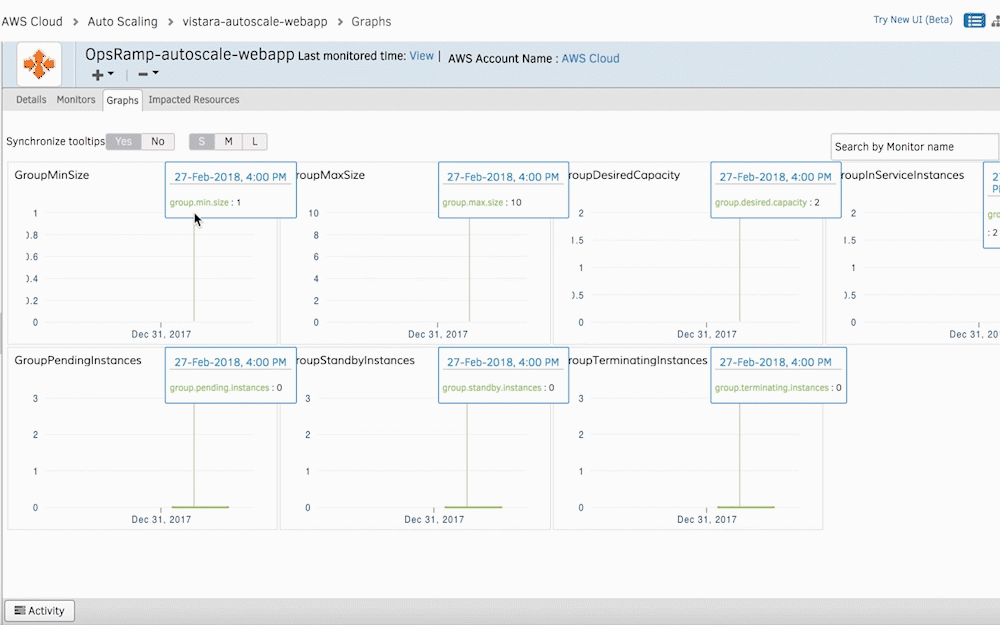
図3-グラフを使用してAWSAutoScalingインスタンスのヘルスとステータスにアクセスします。 - CloudTrailアラームをOpsRampにストリーミングします。 CloudTrailログをOpsRampにストリーミングして、AWS AutoScalingの変更または更新を評価します インフラストラクチャー。 CloudTrailが新しいインスタンスの作成に関するアラートを送信するたびに、OpsRampはこれらの新しいAWSリソースのアドホックディスカバリーを開始します。 Discovery APIは、動的なインフラストラクチャ管理のために、新しいクラウドリソースをOpsRampの監視自動化に取り込みます。
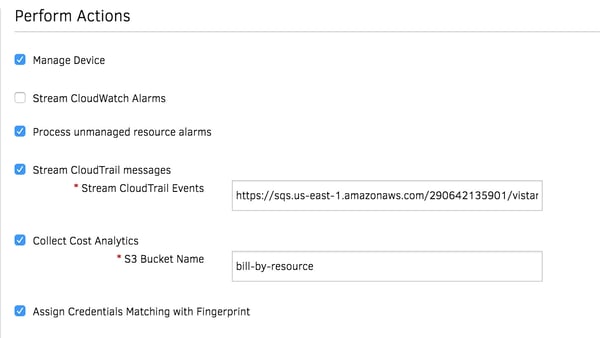 図4-AutoScalingインスタンスのアドホック検出のためのAWSCloudTrailメッセージのストリーミング。
図4-AutoScalingインスタンスのアドホック検出のためのAWSCloudTrailメッセージのストリーミング。
AWS AutoScalingワークロードを常に把握する
AWS Auto Scalingディスカバリーを開始するとすぐに、OpsRampはAPIを介して適切なモニタリングテンプレートを適用し、リアルタイムのパフォーマンスデータをキャプチャします。監視テンプレートは、さまざまな属性にルールを割り当てて、手動プロセスなしで自動スケーリングリソースを管理します。
- フィルタ基準を使用すると、すべてのAWS Auto Scalingリソースを選択し、プロアクティブなインサイトに関連するパフォーマンスメトリックを提示できます。
- エンドツーエンドの管理のために、AWS AutoScalingリソースでさまざまなアクションを開始して実行します。
- ITチームが1か所で最も重要なKPIにアクセスできるように、さまざまなAWSサービスにモニタリングポリシーとナレッジベースの記事を割り当てます。
- A可用性ルールをssignして、可用性、パフォーマンス、エラー、またはその他のカスタムメトリックを使用してAutoScaleインスタンスの現在の状態を理解します。
- カスタム属性を割り当てて、カスタムタグ(場所の名前、リソースの所有者、または連絡先の詳細)を使用してリソースを一括で識別します。カスタムタグは自動スケールインスタンスをグループ化して、これらのワークロードを分析および監視できるようにします 効率的。
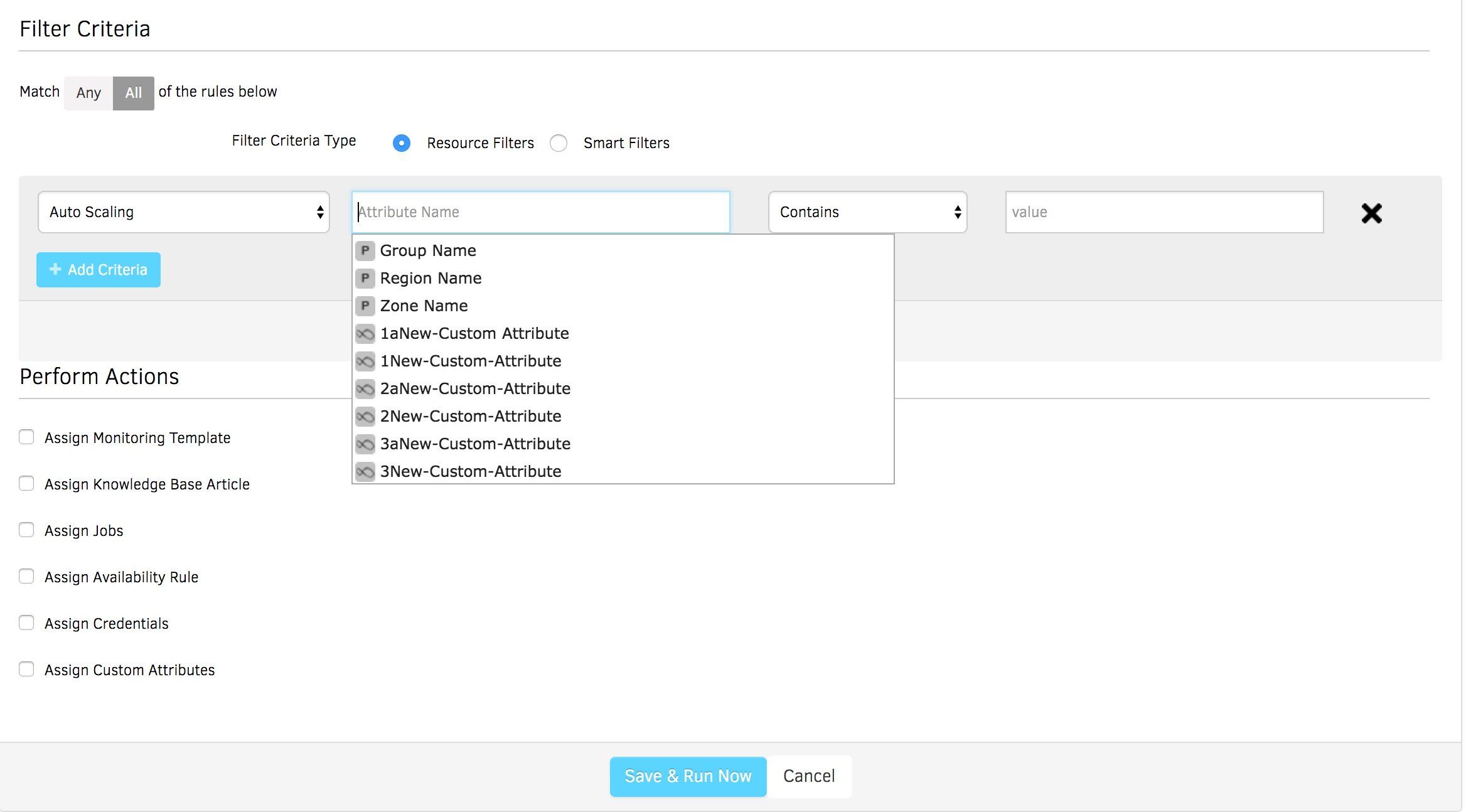
図5-効果的な管理のためにAutoScalingインスタンスにルールを割り当てます。
オペレーショナルダッシュボードは、AWS AutoScalingインフラストラクチャが時間の経過とともにどのように実行されているかを理解するのに役立ちます。ダッシュボードは、AWSリソースをグローバル規模で追跡し、リアルタイムのヘルスと可用性を監視し、重要なサービスのアラートトレンドを表示します。ダッシュボードを使用して、さまざまなAWSサービスのすべての重要なインフラストラクチャメトリック(容量、遅延、使用率、可用性、イベント、アラート)にアクセスします。
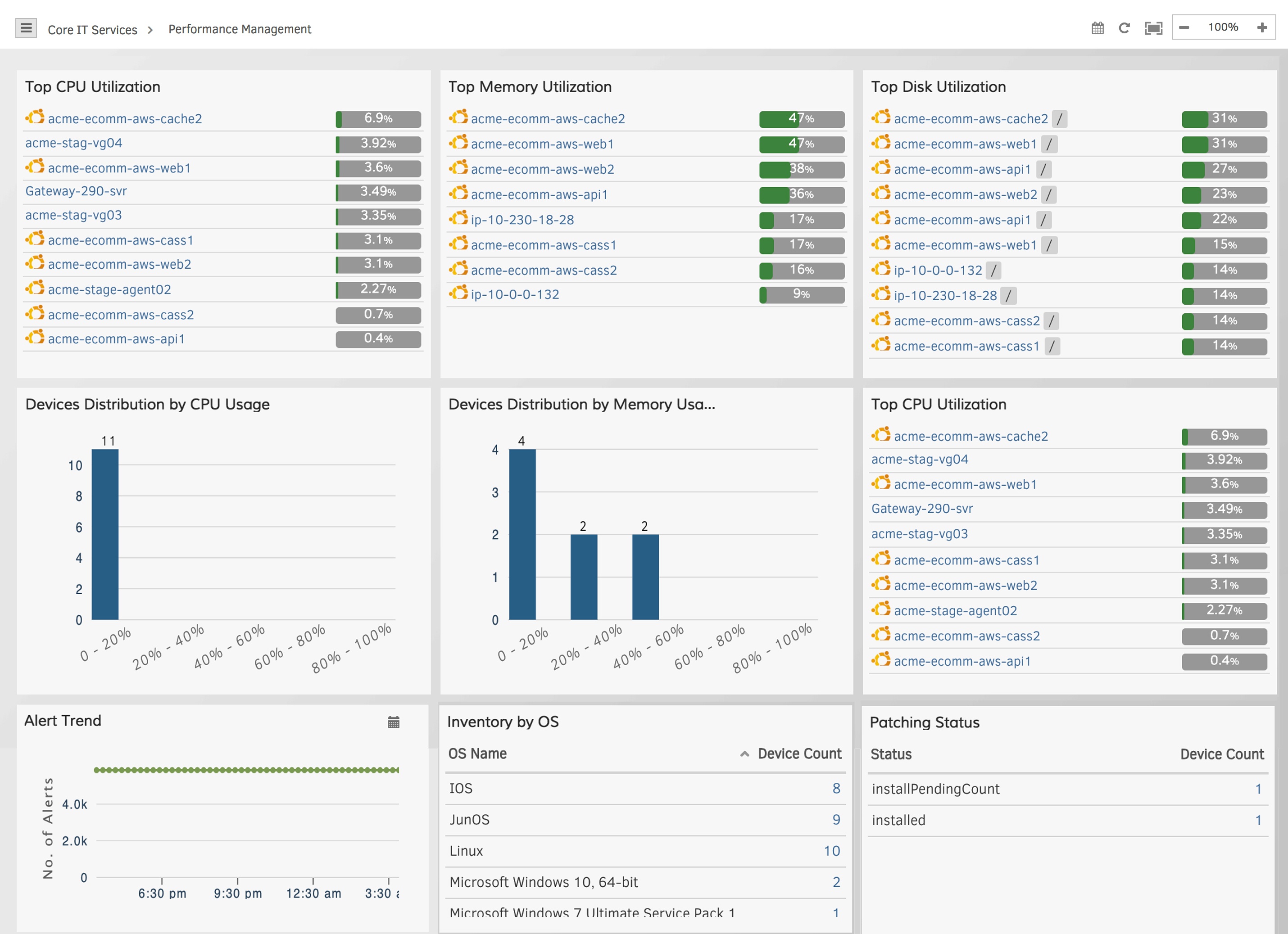
図6-運用ダッシュボードを使用して、AutoScalingワークロードの重要なKPIにアクセスします。
次のステップ:
- 次の策: マルチクラウド可視性ダッシュボード 企業のクラウドサービスと予算をより適切に管理するのに役立ちます。
- 上のデータシートをダウンロードしてください ハイブリッドクラウド管理 .
- 自信を持ってマルチクラウド管理を採用したい場合は、 今日OpsRampソリューションコンサルタントに相談してください .