

Match Your Infrastructure Capacity To Meet Application Demand
One of the biggest challenges with cloud capacity management is finding the most efficient way to handle dynamic application demands. AWS Auto Scaling automatically expands and shrinks your AWS infrastructure capacity based on actual application usage and demand. Auto Scaling is available for a whole host of AWS services, including EC2, ECS, Spot Fleets, DynamoDB, Aurora, AppStream 2.0, and EMR. AWS Auto Scaling lets you select the specific Amazon services that make up your application and choose scaling options for each resource, helping you maintain availability and performance at scale.
Auto Scaling resources come into play for short bursts of time, based on your workload demands. Given the dynamic and ephemeral nature of Auto Scaling instances, how do you gain appropriate insights to manage the health of your cloud-native applications? OpsRamp’s monitoring automation handles autoscaling scenarios in a policy-driven manner with its Discovery Profile engine and operational dashboards for the right visibility.
Policy-Based Discovery for AWS Auto Scaling
OpsRamp auto-discovers your AWS infrastructure and platform services with API-based Discovery Profiles. Once you provide credential sets, define policies, and set the schedule for cloud discovery, the AWS Discovery Profile engine automatically assigns cloud resources to service groups for logically organizing your cloud-native services.
You can either invoke API-based scheduled discovery or consume CloudTrail alarms to track changes for your AWS Auto Scaling instances in OpsRamp. Here’s how OpsRamp drives continuous cloud discovery at scale:
- Scheduled Discovery For Auto Scaling Workloads. OpsRamp’s scheduled discovery scans your AWS resources at defined intervals (minutes, hours, days, weeks, and months) to track changes to your Auto Scale instances. The Discovery API can capture relevant attributes like availability zone, time of creation, desired capacity, maximum and minimum size, and open alerts for AWS Auto Scaling instances.

Figure 1 - Scheduled Discovery helps you track changes to your AWS Auto Scaling resources.Here are the different metrics that you can review for your AWS Auto Scale instances in OpsRamp:
- GroupMinSize - The minimum size of your Auto Scaling group.
- GroupMaxSize - The maximum size of your Auto Scaling group.
- GroupDesiredCapacity - The number of instances maintained by your Auto Scaling group.
- GroupInServiceInstances - The number of instances running in your Auto Scaling group.
- GroupPendingInstances - The number of instances that are not yet in service.
- GroupStandbyInstances - The number of instances that are in a standby state.
- GroupTerminatingInstances - The number of instances that are in the process of terminating.
Figure 2 - Gain the right operational insights for your AWS Auto Scaling instances.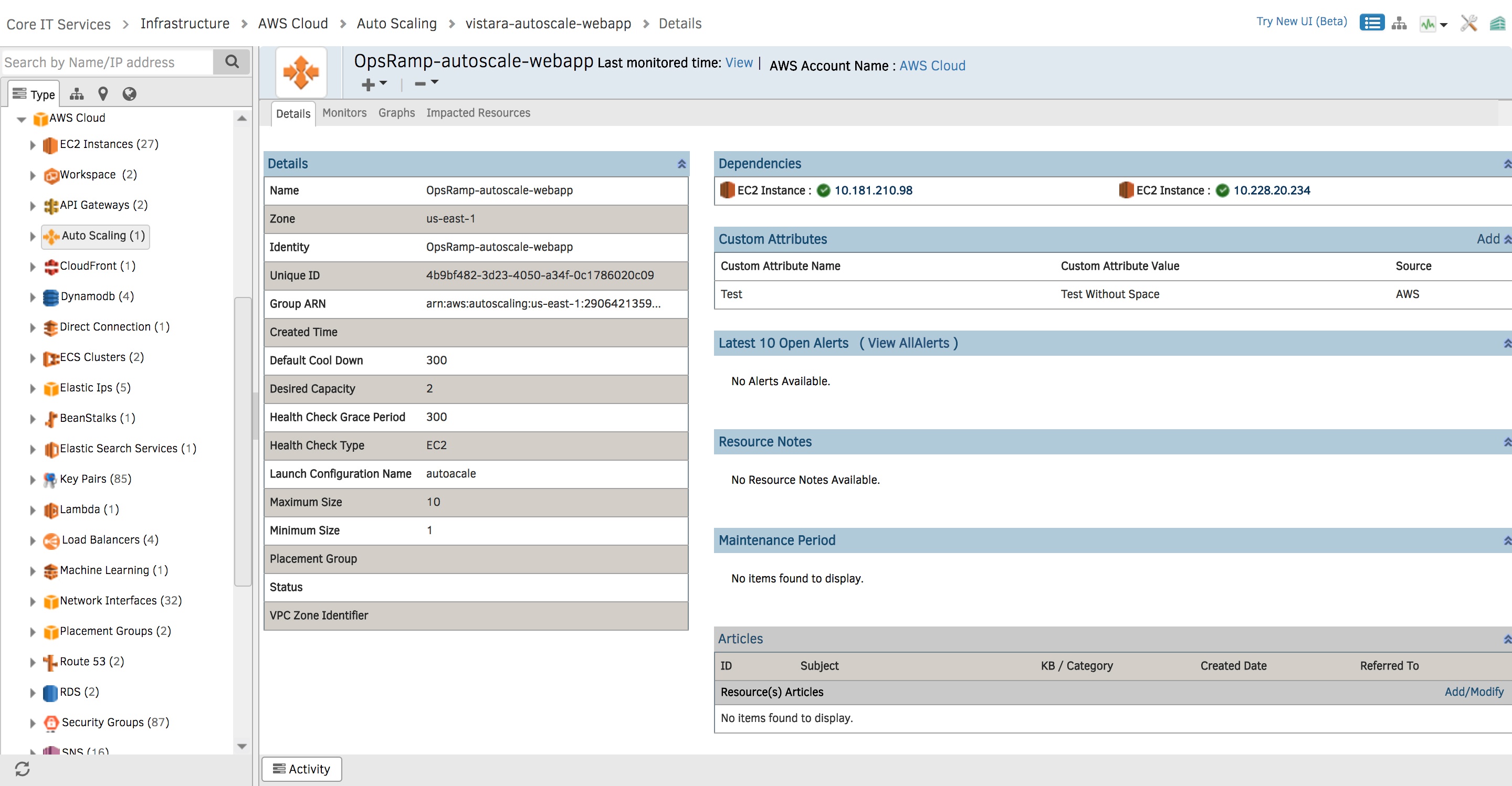
You can visualize AWS Auto Scaling monitoring metrics in the form of graphs. Your IT teams can also set thresholds for specific metrics and receive alerts whenever there’s a deviation.
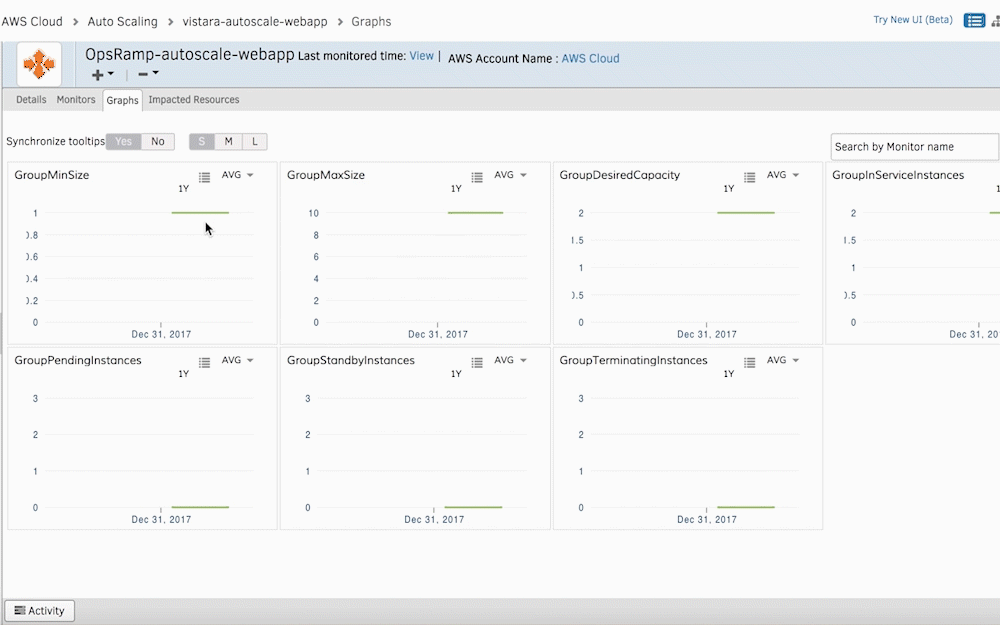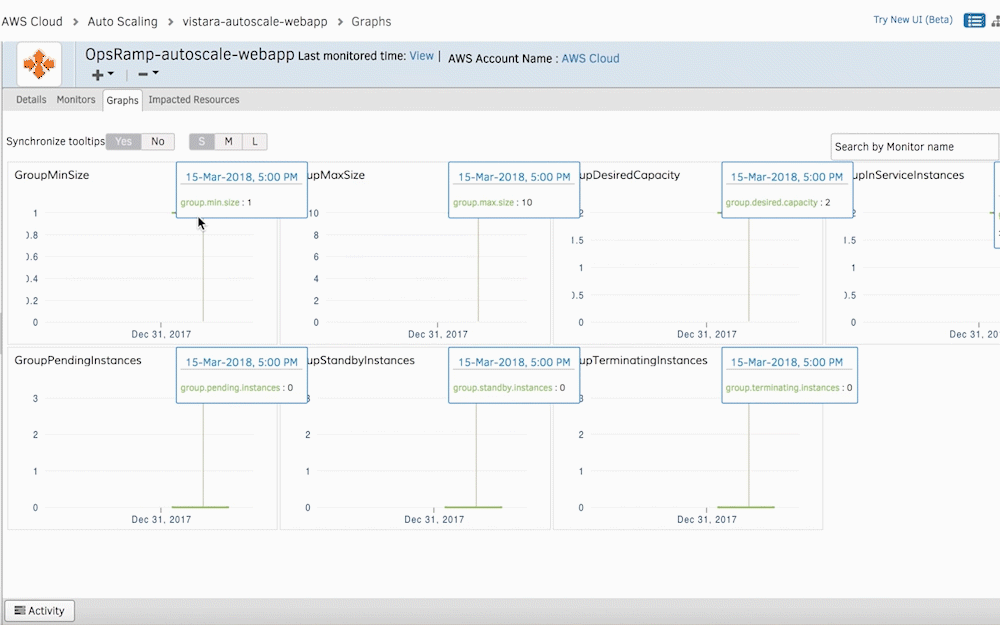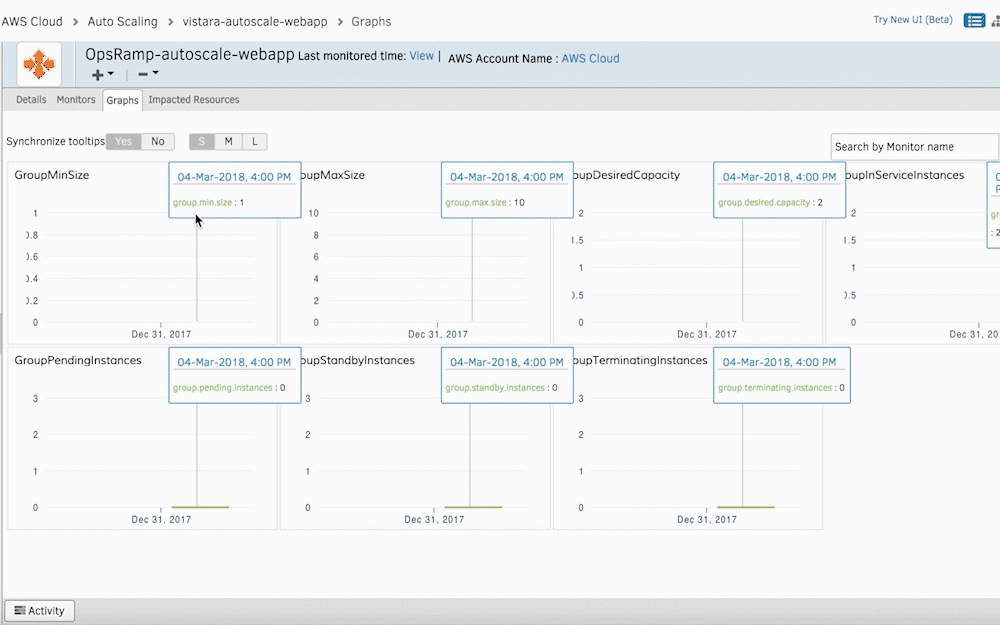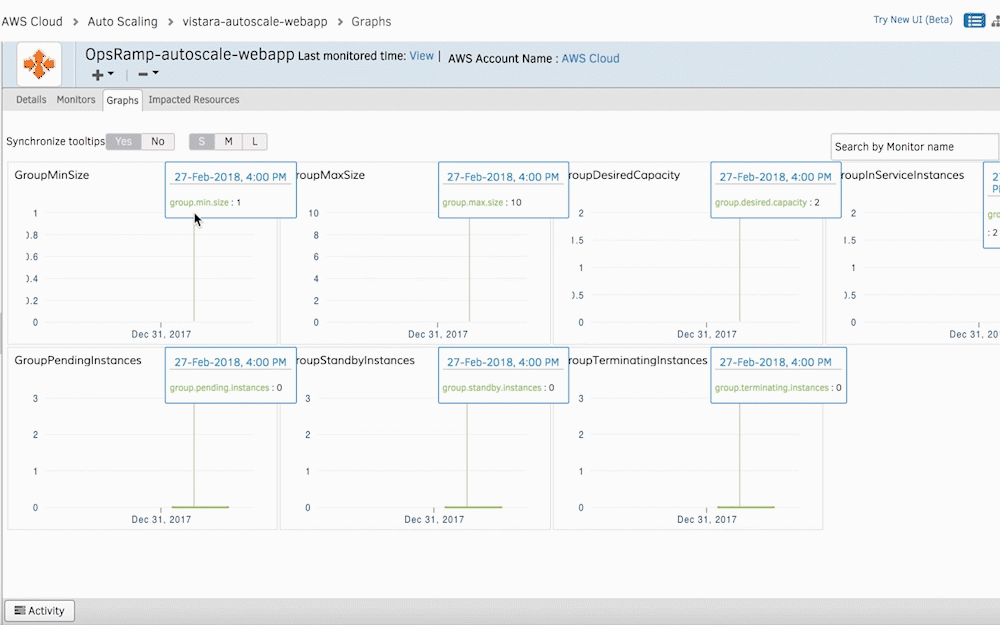
Figure 3 - Access the health and status of your AWS Auto Scaling instances with Graphs. - Stream CloudTrail Alarms Into OpsRamp. Stream CloudTrail logs into OpsRamp to assess changes or updates to your AWS Auto Scaling infrastructure. Whenever CloudTrail sends an alert for the creation of a new instance, OpsRamp initiates ad-hoc discovery for these new AWS resources. The Discovery API captures new cloud resources into OpsRamp’s monitoring automation for dynamic infrastructure management.
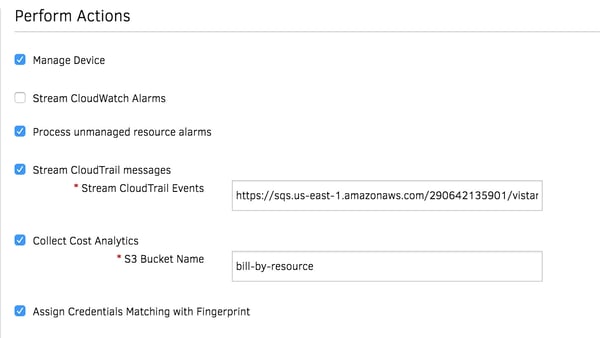 Figure 4 - Stream AWS CloudTrail messages for the ad-hoc discovery of Auto Scaling instances.
Figure 4 - Stream AWS CloudTrail messages for the ad-hoc discovery of Auto Scaling instances.
Stay On Top Of Your AWS Auto Scaling Workloads
As soon as you initiate AWS Auto Scaling discovery, OpsRamp applies the right monitoring templates via APIs to capture real-time performance data. Monitoring templates assign rules to various attributes to manage your auto scaling resources without manual processes:
- Filter criteria let you select all your AWS Auto Scaling resources and present relevant performance metrics for proactive insights.
- Initiate and perform different actions on AWS Auto Scaling resources for end-to-end management:
- Assign monitoring policies and knowledge base articles for different AWS services, so that your IT teams can access the most important KPIs in a single place.
- Assign Availability rules to understand the current state of an Auto Scale instance using availability, performance, error, or other custom metrics.
- Assign Custom Attributes to identify resources with custom tags (location name, resource owner, or contact details) in bulk. Custom tags group autoscale instances so that you can analyze and monitor these workloads efficiently.
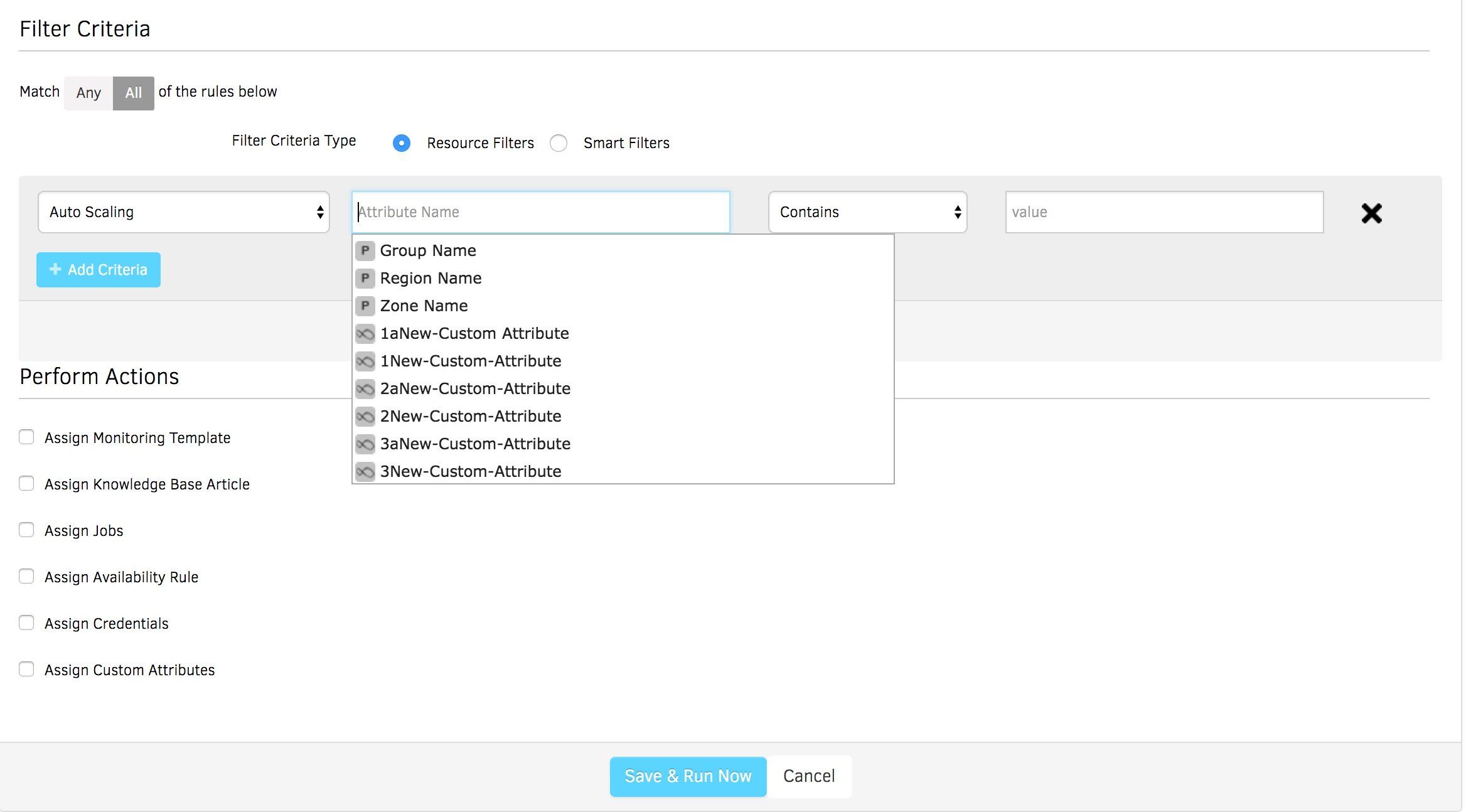
Figure 5 - Assign rules to your Auto Scaling instances for effective management.
Operational Dashboards help you understand how your AWS Auto Scaling infrastructure is performing over time. Dashboards track your AWS resources on a global scale, monitor real-time health and availability, and display alert trends for critical services. Access all your critical infrastructure metrics (capacity, latency, utilization, availability, events, and alerts) for different AWS services using dashboards.
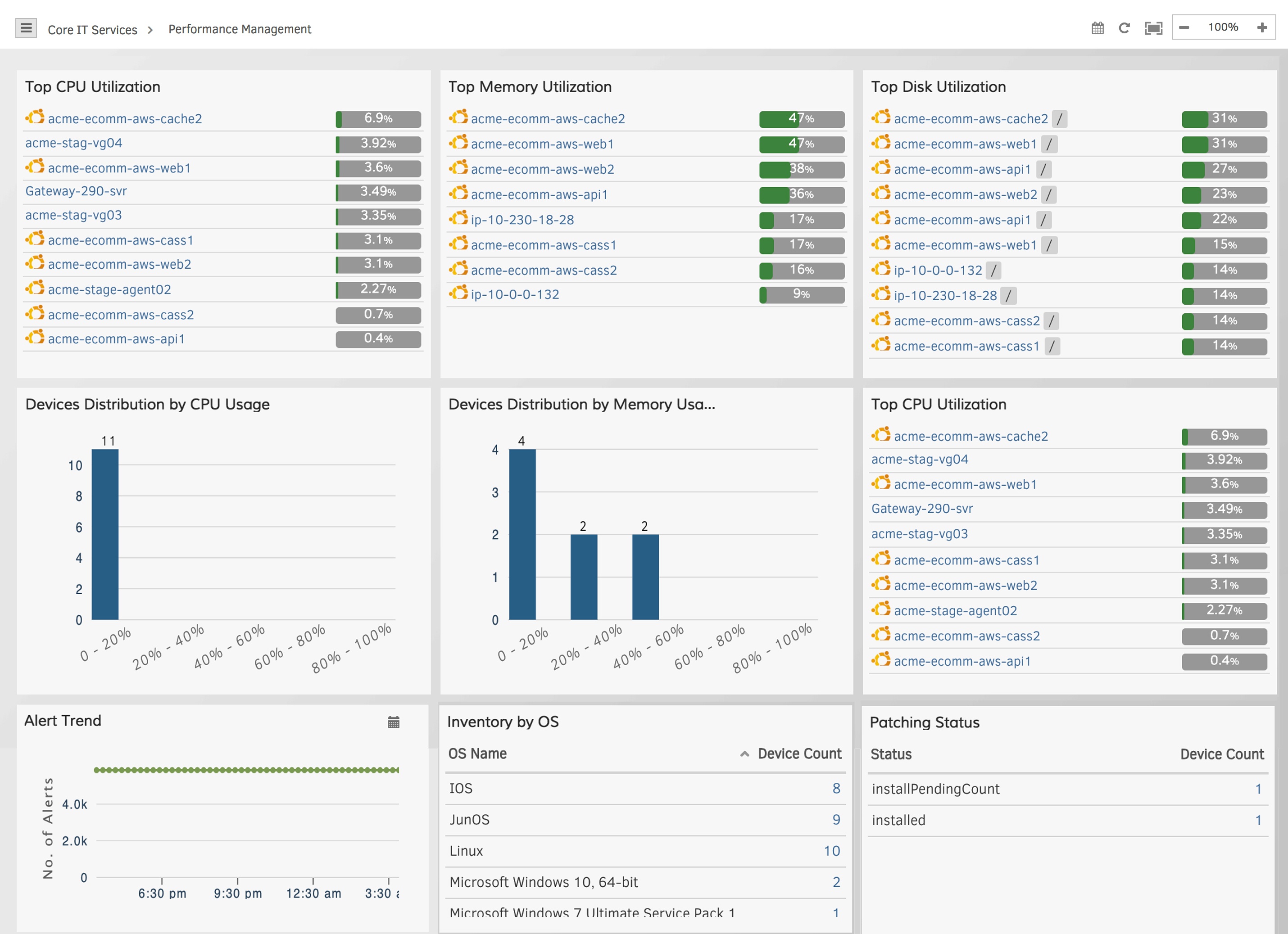
Figure 6 - Access critical KPIs for Auto Scaling workloads with operational dashboards.
Next Steps:
- Learn how OpsRamp’s recently announced Multi-Cloud Visibility Dashboard helps you better manage cloud services and budgets for your enterprise.
- If you’re looking to embrace multi-cloud management with confidence, talk to an OpsRamp solution consultant today.



