


OpsRampウィンターリリースは、インテリジェントなインシデント管理とクラウドネイティブモニタリングを備えたハイブリッドインフラストラクチャ管理のための、より優れたサービス中心性とコンテキストを提供します。 2019年1月のリリースには、サービスマップの新しいUI、強化されたAIOps機能、クラウドネイティブモニタリング機能などのイノベーションが含まれています。
衝撃の可視性& ネットワークトポロジとサービスマップを使用したサービスコンテキスト
OpsRampは、適切なレベルの影響の可視性とサービスコンテキストを提供するため、ビジネスクリティカルなサービスと基盤となるアプリ、ミドルウェア、データベース、およびハイブリッドインフラストラクチャ全体の動的な分散関係を追跡できます。可視性のギャップを減らし、運用上のサイロを排除するサービスコンテキストの最新機能は次のとおりです。
- アプリケーショントポロジマップ。 どのアプリケーションコンポーネントが現在動作しているか、およびこれらのアプリケーションが互いにどのように相互作用するかを把握することは、ほぼシーシュポスのタスクです。 IT環境全体。アプリケーショントポロジマップは、40の人気のあるエンタープライズアプリケーション(Apache、Cassandra、Couchbase、Docker、Hadoop、Kafka、Mesos、MongoDB、MySQL、Redis、Solr、Zookeeper)のエンドツーエンドの依存関係情報を自動的に検出して配信します。 OpsRampは、アプリケーションエコシステムのどこで何が実行され、何が接続されているかを追跡する手間を省き、プロアクティブな可視性と制御のための全体像を提供します。
- ハイパーバイザートポロジマップ。 クラウドのモダナイゼーションイニシアチブに着手する場合、多くの場合、オンプレミスの仮想マシンをパブリッククラウド環境に移行する必要があります。ハイパーバイザートポロジマップは、仮想マシンが実行されている場所と、VMwarevSphereおよびKVM環境で仮想マシンが相互に接続されている方法を視覚化するのに役立ちます。ハイパーバイザーのワークロードと依存関係を正確に評価することで、オンプレミスのフットプリントを自信を持ってクラウドに移行できます。
- サービスマップ。 トポロジマップはアプリケーションまたはインフラストラクチャコンポーネント間の影響関係をキャプチャしますが、サービスマップはエンドユーザーに対するITサービスの影響を表します。サービスマップの各ノードは、そのアプリケーションのユーザーのプロキシとして機能します。 ITアラートを受信すると、新しいサービスマップUIは、影響を受けるエンドユーザーと影響を受けないエンドユーザーを特定するのに役立ちます。また、ユーザーがアプリケーションのパフォーマンスについて不満を言う場合、サービスマップは、どのハイブリッドインフラストラクチャリソースが問題の原因であるかを特定するのに役立ちます。
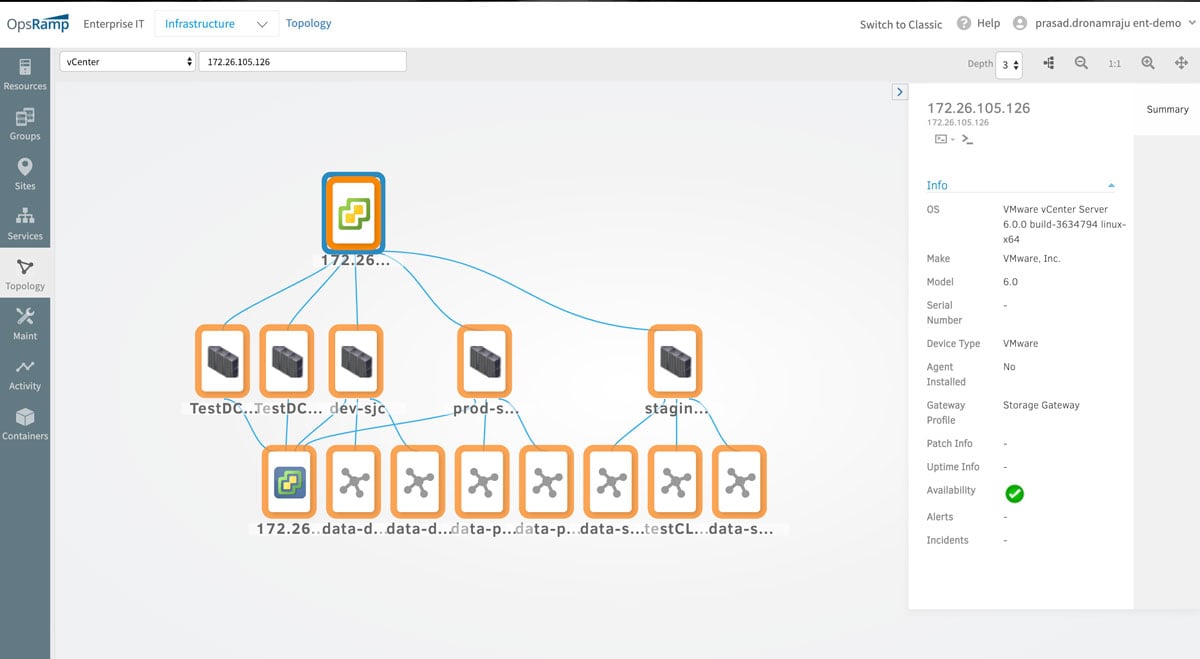
図1:ハイパーバイザートポロジマップは、VMware vSphereおよびKVM環境でVM、ハイパーバイザーサーバー、およびクラスターを検出します
問題の切り分けと影響分析のためのサービス中心のAIOps
OpsRamp OpsQは、ITチームが、実用的で完全なコンテキストITイベントデータを使用して、ビジネスを狂わせる可能性のある重大なインシデントをすばやく把握するのに役立ちます。データ主導の洞察でアラートフラッドを管理するのに役立つ最新のAIOpsイノベーションは次のとおりです。
- 自動インシデントルーティング。 深刻な停止時にインシデント対応を遅らせる主な要因は、インシデントを作成し、運用上の優先順位に基づいて正しく分類し、適切なチームに割り当てるために必要な時間です。完了に伴う手作業を考えると これらすべてのタスクで、OpsRampは機械学習ベースのエスカレーションポリシーを導入しました。これにより、インシデントの優先順位を自動的に学習し、関連するイベントコンテキストを適切なグループに送信できます。自動インシデントルーティングは、重大な停止時の問題認識、インシデントの優先順位付け、およびチケット割り当てに関連する人的時間と労力を削減します。
- アラート推論のための拡張トレーニング。 このリリースでは、お客様が特定のニーズに合わせてOpsQイベント管理エンジンをトレーニングできるようにAIOpsプラットフォームを公開しました。 OpsRamp OpsQには継続的な学習機能があり、観察したパターンから学習を続けることができます。ただし、まれな停止などの特定のパターンは断続的に発生するため、いつ発生するかを検出することが重要です。 IT運用チームは、問題の特定に重要なパターンを認識するようにOpsQをトレーニングできるようになりました。お客様はトレーニングデータを提供して、ITイベント管理データ全体のパターンをより適切に検出するようにOpsQに教えることができます。
- 頻度駆動型アラートエスカレーション。 時折発生するネットワークフラップは、すべてのIT環境で定期的に発生する機能であり、重大な障害を示すものではありません。ただし、アラートフラップが繰り返し発生する可能性があります 永続的な問題の兆候。頻度主導のアラートエスカレーションを使用すると、アラートフラップが時折発生する場合と繰り返される場合を区別し、OpsQを使用してアラートエスカレーションや自動インシデント作成などの自動アクションを実行し、これらの重大な問題を修正できます。
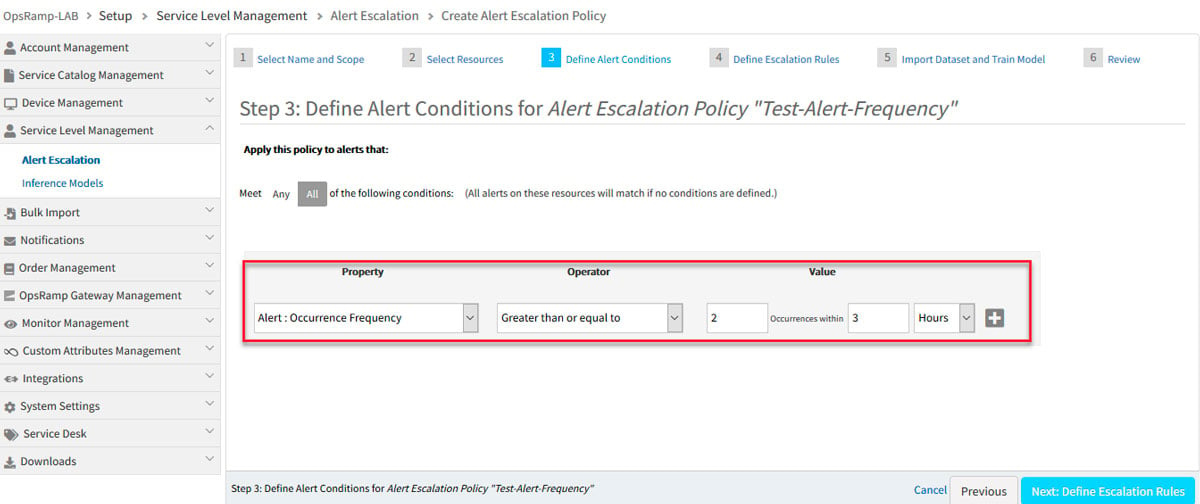
図2: 頻度ベースのアラートエスカレーションを使用すると、たまにしかフラップしないアラートを除外し、繰り返しフラップするアラートをエスカレーションできます。
リアルタイムの可視性のためのクラウドネイティブモニタリングとイベント管理
OpsRampのクラウドネイティブモニタリングは、ITチームが最新のマイクロサービスアーキテクチャをサポートするコンテナインフラストラクチャを発見およびモニタリングするのに役立ちます。クラウドイベント管理は、クラウドイベントから信号を抽出することにより、重大な問題を即座に顧客に通知します。
- コンテナとKubernetesのモニタリング。 OpsRampは、ホストのパフォーマンス、および基盤となるKubernetesとコンテナクラスターの状態に関連する指標を使用して、Kubernetes環境を検出および監視できるようになりました。クラウドネイティブモニタリングは、コンテナをスムーズに実行するのに十分なインフラストラクチャ容量があるかどうかを追跡したり、Kubernetesが適切に自己構成されているかどうかを確認したり、マイクロサービスが適切なスケーリングレベルに構成されているかどうかを理解したりするのに役立ちます。当社のKubernetesモニタリングは、オンプレミス展開と、パブリッククラウド環境で実行されているマネージドKubernetesワークロードの両方に最適です。
-
AWSイベントモニタリング。 エンタープライズパブリッククラウドのデプロイには、通常、さまざまなチームやITサービスにまたがる数百のAWSカスタマーアカウントが含まれます。イベントは、パブリッククラウド環境の可用性とパフォーマンスを監視するための重要な情報源です。イベントは、AWSが計画されたメンテナンスアクティビティについて報告する方法と、PaaSサービスが独自の状態を示す方法です。 OpsRampは、100個のアカウントのそれぞれにログインしなくても、クラウドイベントを集約し、それらを理解し、迅速な修復のためのアクションを実行するための単一の場所を提供するようになりました。
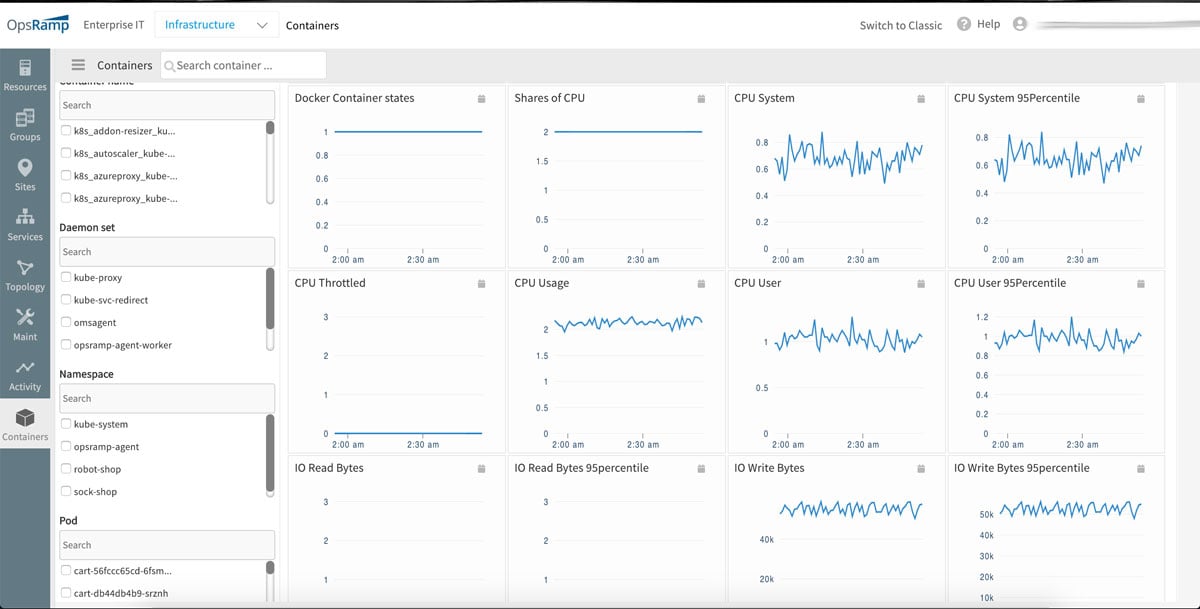
図3: クラウドネイティブモニタリングを使用すると、各Kubernetesクラスターのサービス全体とリソースの傾向を理解できます。
OpsRamp Winter Releaseには、パッチコンプライアンス検証、合成トランザクションおよびSSL証明書の監視のための新しいパッチ管理機能、オープンソースアプリケーションを監視するための新しい統合、および分類とリンクを容易にするためのナレッジベースの拡張機能も含まれています。
それでも不十分な場合は、OpsRamp Winter2019リリースを簡単に紹介します。
次のステップ:
- 私たちを読む2019年冬のプレスリリースKubernetesモニタリング、自動インシデントルーティング、トポロジマッピングを組み合わせて最新のIT運用管理を行う方法をご覧ください。
- 私たちをチェックしてください 新機能ページ 2019年冬のリリースのハイライトについて。
- Schedule a カスタムデモ OpsRampソリューションの専門家と。



