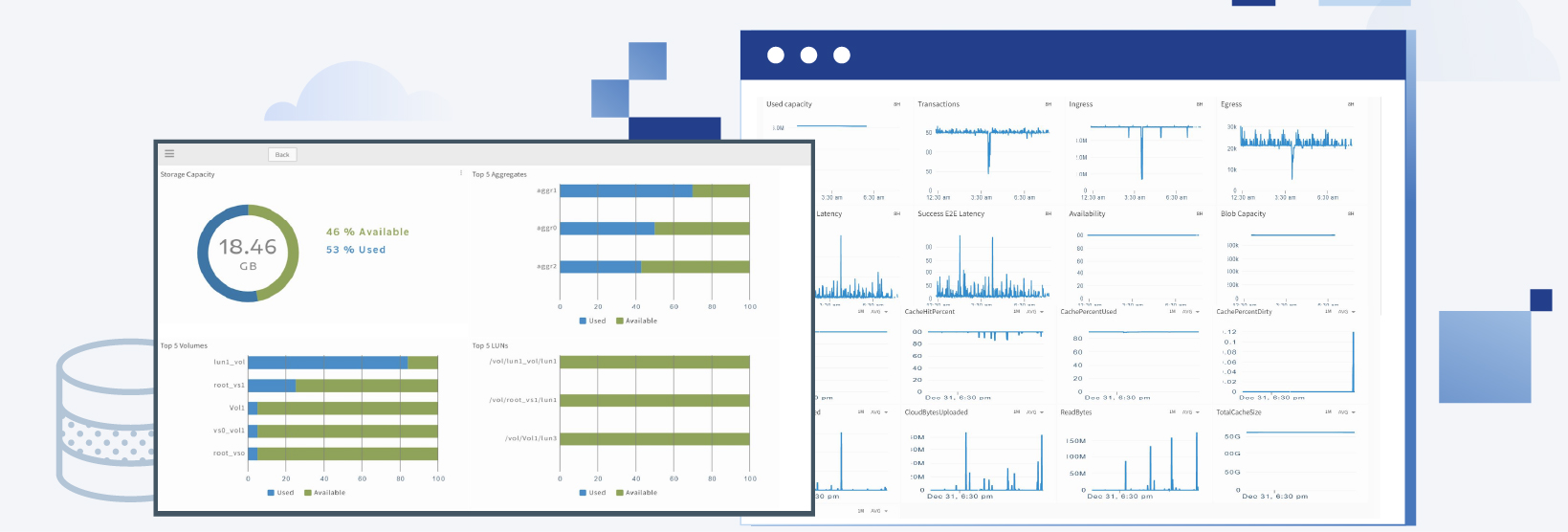
The OpsRamp winter release delivers greater service-centricity and context for hybrid infrastructure management with intelligent incident management and cloud native monitoring. The January 2019 release features innovations such as a new UI for service maps, enhanced AIOps capabilities and cloud native monitoring features.
Impact Visibility & Service Context With Network Topology and Service Maps
OpsRamp delivers the right levels of impact visibility and service context so that you can keep track of dynamic and distributed relationships across business-critical services and underlying apps, middleware, databases, and hybrid infrastructure. Here are our latest capabilities for service context that reduce visibility gaps and eliminate operational silos:
- Application Topology Maps. It is a nearly Sisyphean task figuring out which application components are currently operational and how these applications interact with each other across your IT environment. Application topology maps automatically discover and deliver end-to-end dependency information for forty popular enterprise applications (Apache, Cassandra, Couchbase, Docker, Hadoop, Kafka, Mesos, MongoDB, MySQL, Redis, Solr, and Zookeeper). OpsRamp removes the pain of tracking what’s running and what’s connected where in your application ecosystem with a complete picture for proactive visibility and control.
- Hypervisor Topology Maps. When you embark on a cloud modernization initiative, it often involves migrating your on-prem virtual machines to a public cloud environment. Hypervisor topology maps help visualize where your virtual machines are running and how they are connected to each other in VMware vSphere and KVM environments. You’ll be able to confidently migrate your on-prem footprint to the cloud with an accurate assessment of hypervisor workloads and dependencies.
- Service Maps. While topology maps capture impact relationships across application or infrastructure components, service maps represent the impact of IT services on end-users. Each node in a service map serves as a proxy for users of that application. When you receive an IT alert, the new service maps UI helps pinpoint which end-users are impacted and which ones are not. Also, when users complain about application performance, service maps help isolate which hybrid infrastructure resources are responsible for the issue.
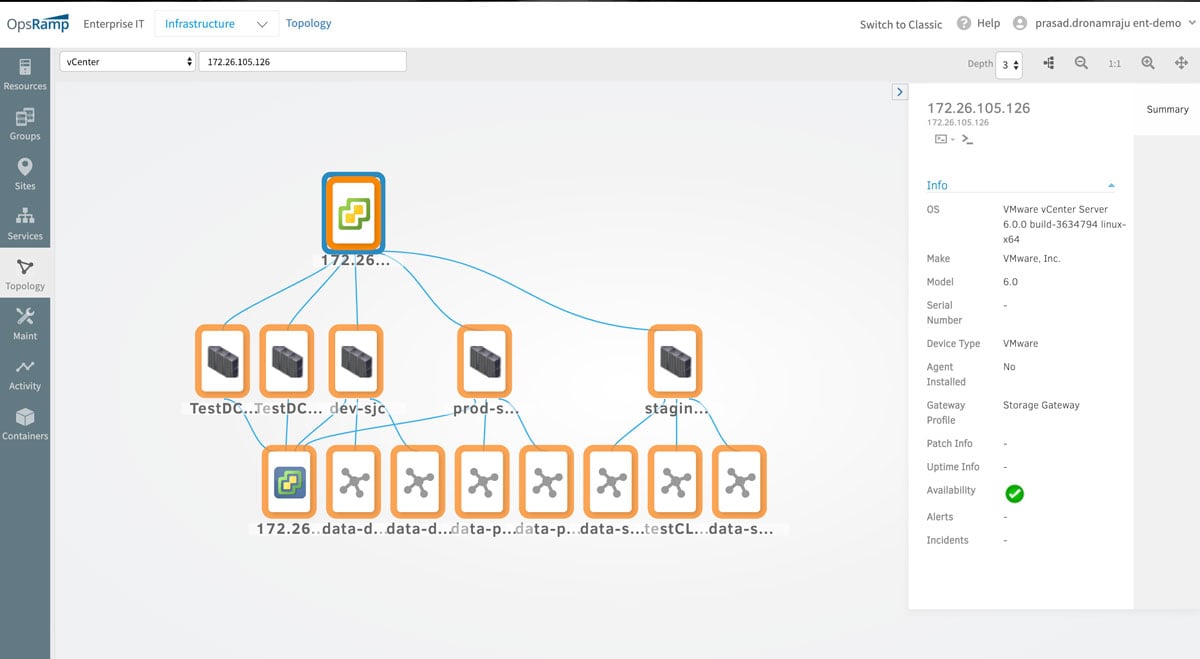
Figure 1: Hypervisor topology maps discover VMs, hypervisor servers and clusters in VMware vSphere and KVM environments
Service-Centric AIOps for Problem Isolation and Impact Analysis
OpsRamp OpsQ helps IT teams quickly figure out the critical incidents that can derail the business with actionable, complete, and contextual IT event data. Here are our newest AIOps innovations that can help you manage alert floods with data-driven insights:
- Auto-Incident Routing. During severe outages, a key factor slowing down incident response is the amount of time needed to create an incident, classify it correctly based on operational priorities, and then assign it to the right teams. Given the manual effort involved in completing all these tasks, OpsRamp has introduced machine learning-based escalation policies which can automatically learn about incident priorities and send relevant event context to the appropriate groups. Auto-incident routing cuts down the human time and effort involved in problem recognition, incident prioritization, and ticket assignment during a critical outage.
- Augmented Training for Alert Inferencing. With this release, we have opened up our AIOps platform so that customers can train the OpsQ event management engine to their specific needs. OpsRamp OpsQ has continuous learning capabilities that allow it to keep learning from the patterns that it observes. However, certain patterns like infrequent outages occur intermittently and are important to detect when they do take place. IT operations teams can now train OpsQ to recognize the patterns that are critical for issue identification. Customers can provide training data to teach OpsQ to better detect patterns across IT event management data.
- Frequency-Driven Alert Escalation. Occasional network flaps are a regular feature in every IT environment and not indicative of any serious failures. However, the repetitive occurrence of an alert flap could be symptomatic of a persistent issue. Frequency-driven alert escalation allows you to distinguish between an occasional and repetitive alert flap and then use OpsQ to take automated actions like alert escalation and auto-incident creation to fix these serious issues.
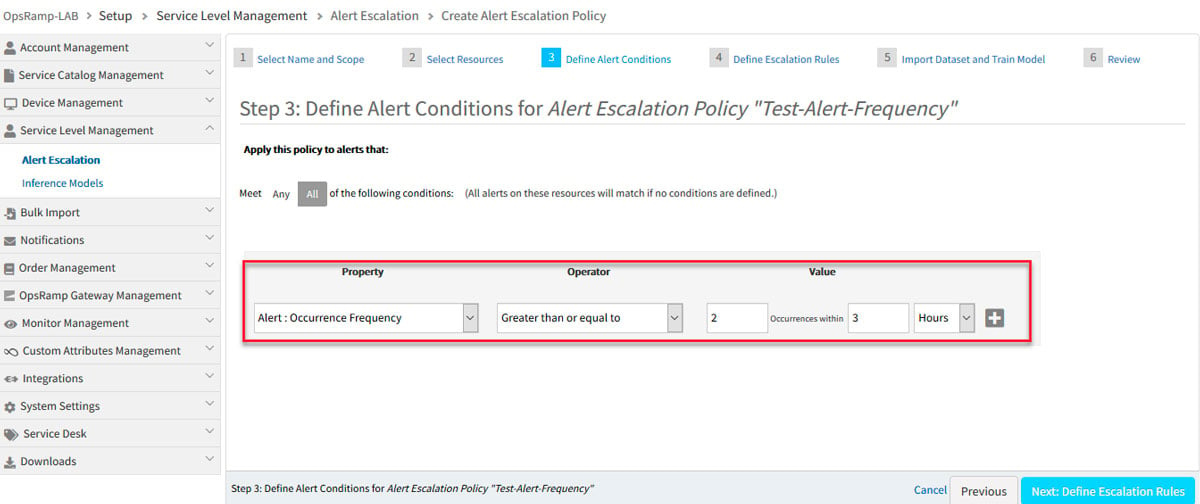
Figure 2: Frequency-based alert escalation lets you filter out alerts that flap only occasionally and escalate alerts that flap repeatedly.
Cloud Native Monitoring and Event Management for Real-Time Visibility
Cloud native monitoring in OpsRamp helps IT teams discover and monitor the container infrastructure that supports modern microservices architectures. Cloud event management immediately notifies customers of critical issues by extracting signal from cloud events.
- Container and Kubernetes Monitoring. OpsRamp can now discover and monitor Kubernetes environments with relevant metrics for host performance as well as the health of underlying Kubernetes and container clusters. Cloud native monitoring helps track if there is enough infrastructure capacity to run your containers smoothly, check if your Kubernetes has been self-configured properly, or understand whether your microservices are configured to the right scaling levels. Our Kubernetes monitoring works great for both on-prem deployments as well as managed Kubernetes workloads running on public cloud environments.
-
AWS Event Monitoring. Enterprise public cloud deployments typically involve hundreds of AWS customer accounts across different teams and IT services. Events are a key source of information for monitoring the availability and performance of public cloud environments. Events are how AWS reports on its planned maintenance activities and how PaaS services present their own health. OpsRamp now provides a single place to aggregate cloud events, make sense of them, and take action for rapid remediation, without having to log into each of your hundred accounts.
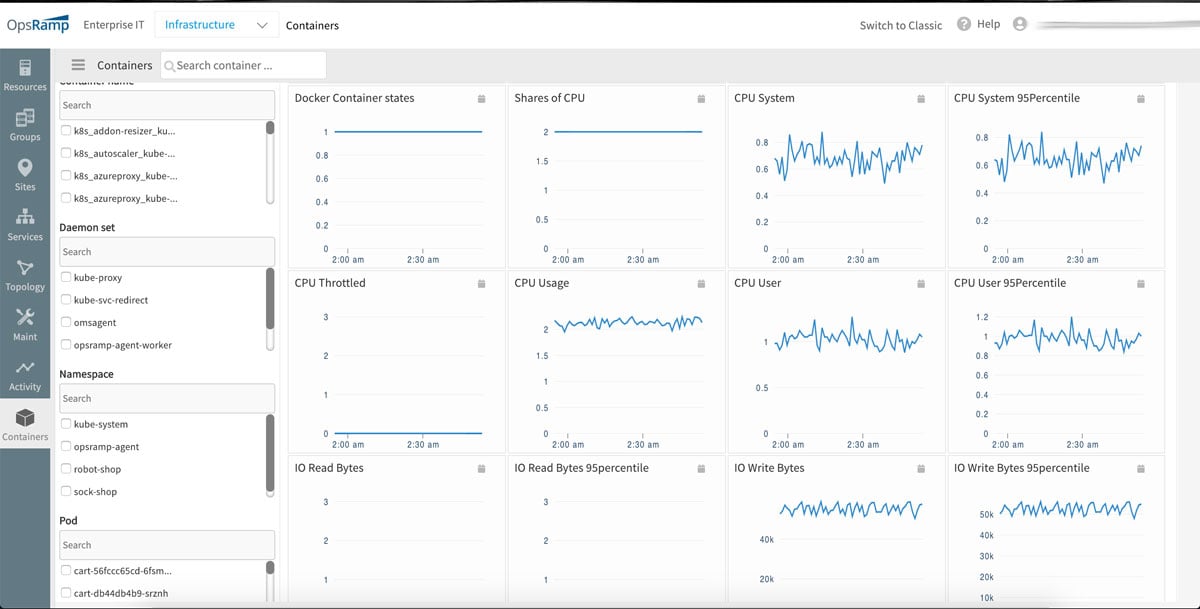
Figure 3: Cloud native monitoring lets you understand the total services and resource trends for each Kubernetes cluster.
The OpsRamp Winter Release also includes new patch management capabilities for patch compliance verification, synthetic transaction and SSL certificate monitoring, new integrations for monitoring open source applications, and knowledge base enhancements for easier categorization and linking.
And if that’s not enough, here is a quick peek into the OpsRamp Winter 2019 release:
Next Steps:
- Read our Winter 2019 press release to see how we combine Kubernetes monitoring, auto-incident routing, and topology mapping for modern IT operations management.
- Check out our What’s New page for the highlights of the Winter 2019 release.
- Schedule a custom demo with an OpsRamp solution expert.