

Better data and actionable insights are only the beginning.
Greater Choice and More Complexity for AIOps Buyers
By 2022, Gartner predicts that 40% of large enterprises will adopt AIOps solutions to cope with never-ending alert floods and ensure faster recovery from disruptive IT outages. The AIOps market is experiencing rapid growth with explosive enterprise adoption, accelerated revenue growth and continued investments from IT operations players. While stand-alone point tools have defined and shaped the AIOps market till date, a number of adjacent vendors are either building or acquiring companies to assemble competitive AIOps portfolios:

Figure 1 - Monitoring, Alerting and Log analytics companies are all aggressively targeting the AIOps market.
Some of the notable AIOps acquisitions over the last few years include:
-
In 2015, Splunk acquired anomaly detection startup Metafor, for its IT operations analytics capabilities. In 2016, Splunk announced its IT Service Intelligence product that uses machine learning to predict and prevent IT service outages.
-
In 2015, PagerDuty bought Event Enrichment HQ and then launched its Event Intelligence product to deliver the right insights for better operational health.
-
In 2017, Cisco AppDynamics announced the purchase of streaming-data company Perspica. In 2019, AppDynamics launched its Cognition Engine, bringing AIOps capabilities to application performance monitoring.
-
2018 witnessed the exit of two small AIOps vendors, Savision (acquired by Martello Technologies Group) and Evanios (purchased by HP).
-
In 2019, New Relic announced its acquisition of SignifAI, a startup focused on faster and smarter incident resolution with machine intelligence.
End Swivel-Chair IT Operations with Service-Centric AIOps
Given the fierce competition and resulting confusion in the AIOps market, how do DevOps and SRE teams pick the right AIOps solution for modern-day incident management? At OpsRamp, we launched our Service-Centric AIOps solution with the singular vision of “eliminating up to 95% of the human time spent on IT event management.”
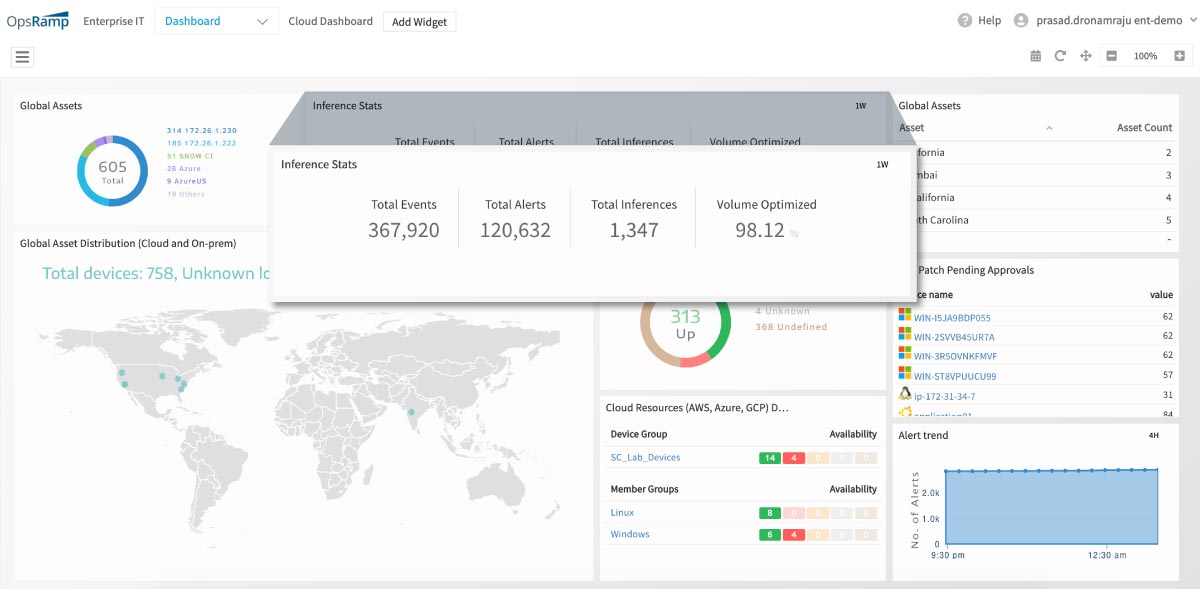
Figure 2 - OpsRamp Service-centric AIOps: Incident management superpowers for faster troubleshooting.
OpsRamp takes a holistic approach to address the problems of alert fatigue, constant firefighting, and IT staff burnout with a comprehensive IT outage lifecycle solution:
-
Service Context. OpsRamp’s service context is all about understanding and presenting contextual relationships for hybrid applications, infrastructure resources and operational aspects of the business service. Service context combines OpsRamp’s capabilities for policy-based discovery, topology models and service maps to present holistic visibility and predict business impact for IT event stream analysis.
-
Intelligent Alerting. OpsRamp’s native instrumentation delivers actionable insights using relevant metrics for both legacy and modern workloads. Dynamic, change-based and forecast-based alert thresholds help IT teams understand the true state of dynamic infrastructure resources. OpsRamp only generates events when it detects a significant change in the underlying IT environment that requires attention and prioritization.
-
Event Correlation. Both native and third-party alerts processed by OpsRamp carry a lot of context. The OpsQ event management engine applies the right inference models for analyzing, deduplicating and reducing event volume with data science techniques and machine learning algorithms.
-
Automated Remediation. OpsRamp applies programmatic remediation for well-defined IT operational issues and invokes the right responses (reboot a server or restart a process) with software-controlled actions. DevOps teams have the option of resolving incidents with automated actions wherever possible so that human operators have fewer events to view, analyze or triage.
Why Point Tools Miss The Point
While stand-alone AIOps tools can flag critical event patterns, OpsRamp’s service-centric AIOps solution combines data, context and insights for end-to-end incident management. With OpsRamp, DevOps teams can handle incident workflow activities like event recognition, impact analysis, root cause identification, incident escalation, and automated remediation in a single place.
Here are four reasons why OpsRamp wins the battle against AIOps point tools for real-time IT event insights, proactive incident response and service health management:
-
Data Quality with Native Instrumentation. The best machine learning algorithms in the world are all bound by the quality of data you feed into them. Unless you can control the IT event data quality and formats at the source, you end up with sub-optimal pattern recognition and detection outcomes. OpsRamp ensures better data quality by controlling data inputs and avoiding fragility with purpose-built data. OpsRamp OpsQ applies data models, metadata and expert recommendations for third-party events from a diverse integrations ecosystem to improve and enhance external data quality over time.
-
Impact Analysis for Faster Troubleshooting. To make sense of an event and know how to fix it, you need to understand its service context. Absent this context, users have no basis to prioritize one incident over the other. OpsRamp’s topology maps and service groups allow IT teams to understand the context behind a specific event and apply impact analysis for faster service restoration.
-
Incident Resolution with Relevant Metrics. How do you resolve an issue once you’ve performed event correlation? Metrics help you isolate the problem, understand an issue with the right performance indicators, and ensure that you are resolving the incident correctly. AIOps tools can only address a slice of the incident management puzzle without access to performance monitoring metric data.
-
Reduced Event “Smog”. While not all failures are auto-remediable, the increasing adoption of software-defined environments means that you can handle a greater percentage of incidents with automation. Stand-alone AIOps tools lack self-healing operational workflows that can fix issues without human intervention.

Figure 3 - Here’s why OpsRamp is the right AIOps platform for real-time incident management.
Next Steps:
- Learn more about OpsQ, service-centric AIOps from OpsRamp.
- Download our Cloud Skills Crisis Report here.
- Schedule a custom demonstration with a solution consultant today.
![[Report] Top Trends In AIOps Adoption](https://blog.opsramp.com/hs-fs/hubfs/Blog_images/AIOps%20Adoption%20Report%20/CTA-AIOps-Adoption.jpg?width=2459&name=CTA-AIOps-Adoption.jpg)


