


IT operations departments in larger enterprises often use 10-15 monitoring tools across different teams to track the health and availability of their core business services. Rather than helping ITOps teams gain a comprehensive view of their infrastructure, an overload of monitoring tools tends to only compound organizational silos and limit insights for incident troubleshooting. Yes, there is too much of a good thing.
A modern digital operations management platform, on the other hand, compiles diverse data sources, streamlines routine processes, and applies analytics to improve outcomes and agility for the enterprise. Given the firehose of diverse events and alerts that IT organizations face on a daily basis, digital operations management solutions have new requirements:
- Incorporate machine learning and data science to reduce false alarms,
- Identify the most probable cause(s) for a service degradation, and;
- Execute automated remediation for common issues and outages.
The end goal is to ensure awesome user experiences and drive business initiatives. Here’s how OpsRamp is meeting these needs in hybrid IT environments.
OpsRamp AIOps: Big Data Analytics for Digital Operations Management
OpsRamp was built from the ground-up as a modern platform for technology operators to monitor their hybrid cloud infrastructure, act when and where it matters, and fix operational issues at scale with automation. Our big data platform combines a data lake, data warehouse, and data hub for processing both structured and unstructured data and delivering analytics and predictions for incident response. What powers this is our AIOps engine.
OpsRamp’s central event management model ingests and analyzes both native and third-party events. You can use OpsRamp’s open integration framework to consume any type of event data source across different channels such as email, traps, or webhook.
Here are 10 ways that OpsRamp AIOps can help IT teams save time and effort for incident diagnosis, troubleshooting, and response:
- Scale for Success. IT operators save time and manage risk using a highly scalable platform that consumes millions of events daily and delivers contextual inferences for faster root cause analysis.
- Have an Integration Party. You can deploy out-of-the-box event integrations for a wide variety of application, infrastructure, and log monitoring tools including: Amazon CloudWatch, AppDynamics, Azure Monitor, Datadog, Dynatrace, Elastic, Google Cloud Operations Suite, Logz.io, Micro Focus Operations Manager i, Prometheus, SignalFx, Site24*7, SolarWinds, Splunk, Sysdig, ThousandEyes, and Zabbix.
- Get Rid of Duplicate Events. Our intelligent event management engine, OpsQ, brings together related duplicate events into a single correlated event (aka inference), helping IT teams reduce alert overload and focus on critical issues. Best of all, operators do not need to build manual rules to configure the OpsQ event management engine.
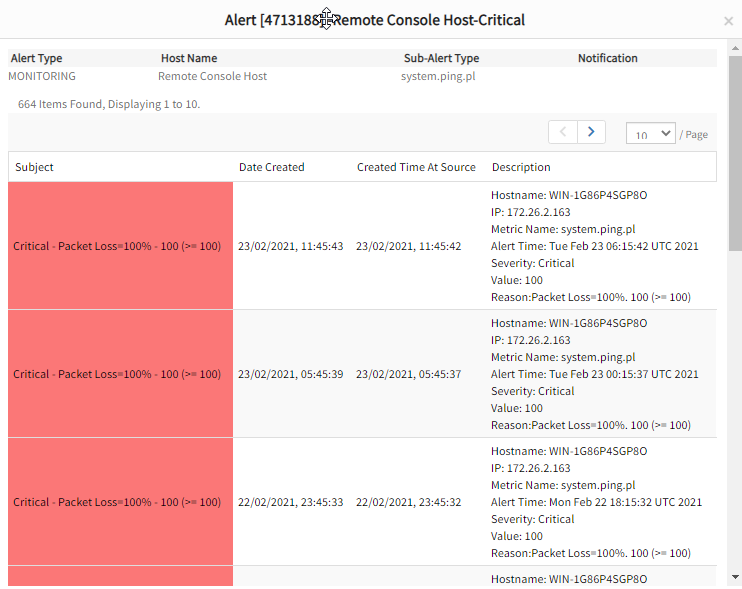
Access the right context for critical IT events that you need to address - Recognize Unknown Event Patterns. We have been talking about applying machine learning and data science to hybrid infrastructure management for a while. That’s important because incident responders can identify probable root cause for an IT outage without having to manually apply rules and filters. Machine learning algorithms can identify relevant patterns across native and third-party events and alert operations teams about atypical events.
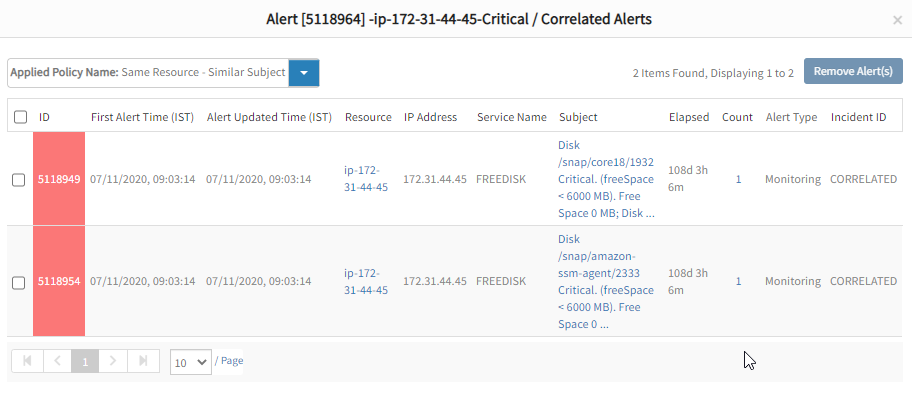
Sort and view related IT events using machine learning and data science - Correlate Events on Time. When you need to look at specific time windows during investigations and analysis, OpsRamp can combine pattern matching with time-based correlation. You can use many event attributes such as metrics, component, description, subject, event source, and resource type to identify events with similar attributes that occur during the same time.
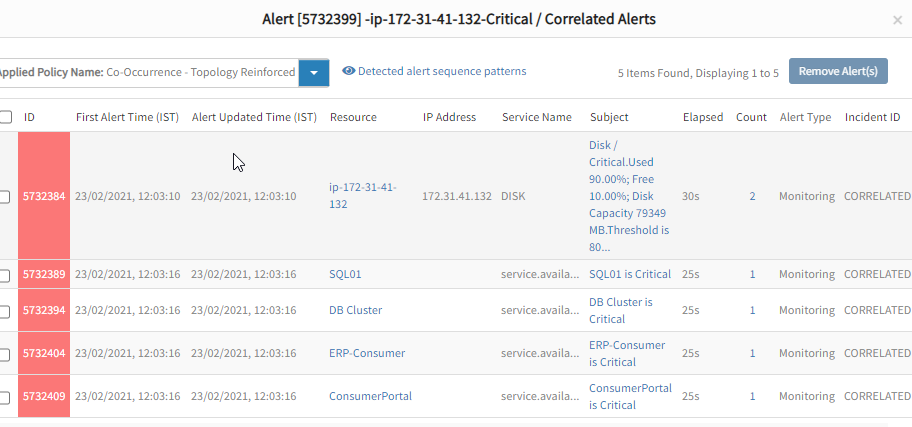 Analyze IT events with similar attributes using time-based correlation
Analyze IT events with similar attributes using time-based correlation - Eliminate Seasonal Alert Noise. OpsRamp uses machine learning algorithms to identify seasonal alerts and can either automatically suppress them or deliver recommendations for suppression. You can also check seasonality pattern widgets for historic and current alert recurrence trends. If an alert matches a recurring pattern, you can safely ignore it.
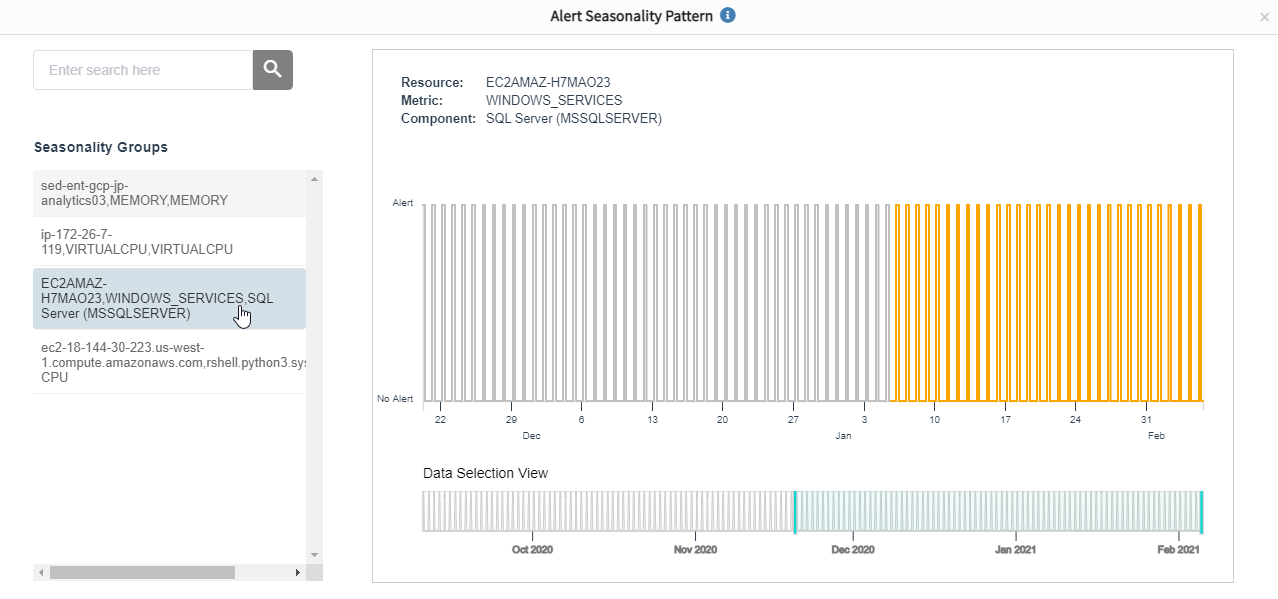 Ignore recurring alerts using our Seasonality Grouping widgets
Ignore recurring alerts using our Seasonality Grouping widgets - Control Annoying Event Flapping. Infrastructure performance metrics commonly fluctuate over a short period of time, which results in events with differing levels of severity popping up and creating ample confusion. OpsRamp correlates severity changes for a specific metric on a particular resource so that you aren’t overwhelmed by flapping event distractions.
 Focus on alerts that flap repeatedly in your hybrid IT environment
Focus on alerts that flap repeatedly in your hybrid IT environment - Snooze Alerts and Avoid Fire Drills. IT teams can snooze escalation of alerts to notifications or incidents for a specific duration. Some alerts automatically heal and disappear by the next polling interval. Snoozing them helps avoid wasting your time chasing down irrelevant or redundant alerts.
- Save Time with Automated Incident Management. OpsRamp’s alert escalation management automatically sends contextual notifications across multiple channels such as email, text, and voice and ensures that the right people receive the information at the right time. Incident managers also have the option of natively creating incidents within OpsRamp or using our native integrations with popular IT service management tools such as ServiceNow, Cherwell, BMC Remedy, Ivanti, and Freshservice. This means that operators can create, address, and remediate incidents either in OpsRamp or a third-party ITSM tool.
- Resolve Issues Faster. You can execute remediation workflows on an infrastructure resource straight from the alert console. The process automation engine can invoke first-response actions for an alert so that users never know the difference.
Next Steps:



