

In the ever-evolving and fast-changing landscape of cloud computing and modern software development, achieving 360-degree visibility into your critical business services, applications and infrastructure is essential. This is where observability comes into play. Observability, especially in a cloud-based or cloud-native environment, has become a critical aspect of maintaining and optimizing complex systems and services. In this blog post, we'll explore what cloud and cloud-native observability mean, why they matter, and how they differ from traditional monitoring practices and approaches.
Understanding Observability
Observability is the capability to gain insight into the internal state and behavior of a system based on its external outputs. It is a fundamental concept in the world of software development and operations, as it allows teams to understand how their applications are performing, identify issues, and resolve problems quickly and effectively.
Traditional monitoring tools typically rely on predefined metrics and alerts—think response times or page load times--which often aren't sufficient for modern, dynamic, and distributed systems and applications. This is where cloud and cloud-native observability become important, providing a more holistic and adaptive approach.
Cloud Observability
Cloud observability focuses on monitoring and gaining insights into applications and infrastructure hosted on cloud platforms like AWS, Azure, or Google Cloud. It involves tracking the performance, availability, and cost of cloud resources to ensure they meet the desired objectives.
Key components of cloud observability include:
Logs: Collecting and analyzing log data from various cloud services and applications to gain visibility into system behavior and troubleshoot issues.
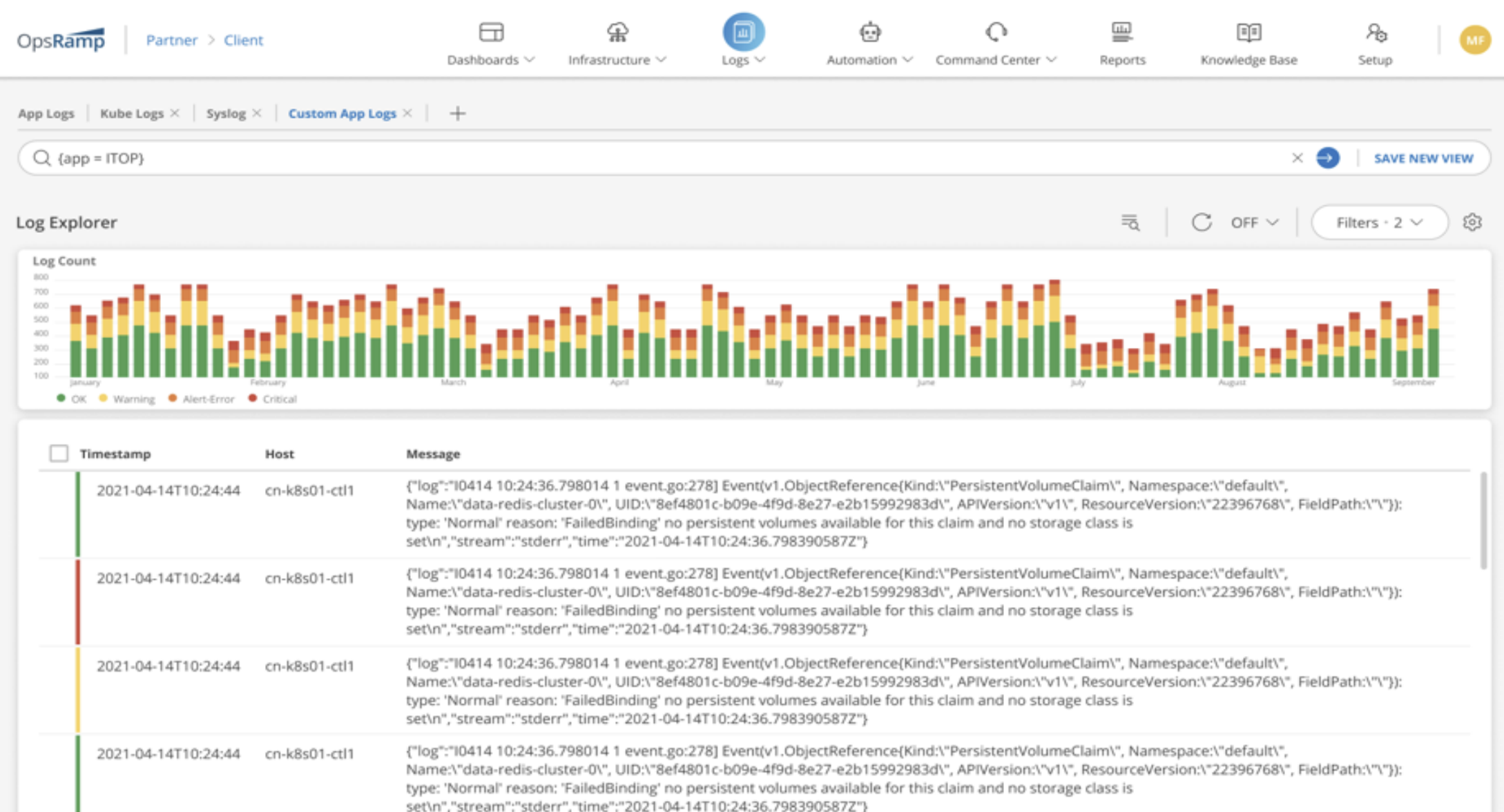 Figure 1: Log management in OpsRamp
Figure 1: Log management in OpsRamp
Metrics: Gathering and visualizing performance metrics, such as CPU utilization, memory usage, and network traffic, to understand the health of cloud resources.
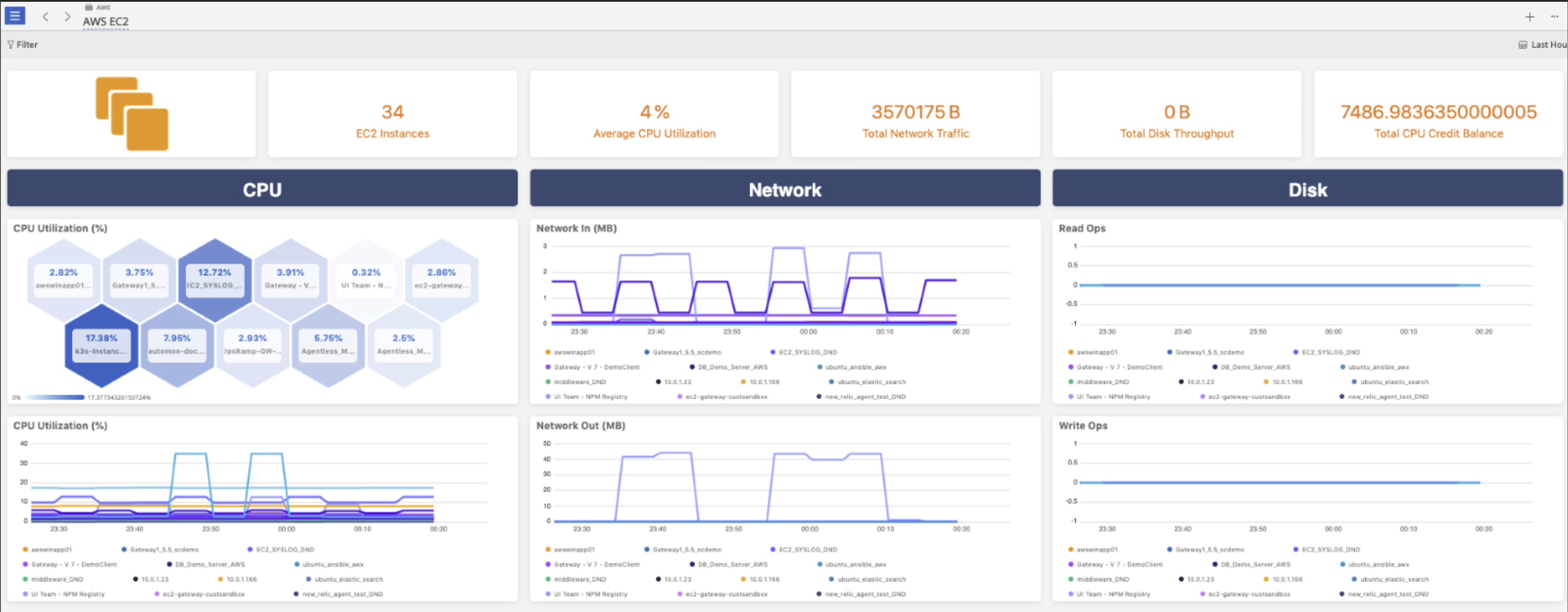 Figure 2: A dashboard view of cloud infrastructure metrics in OpsRamp
Figure 2: A dashboard view of cloud infrastructure metrics in OpsRamp
Tracing: Using distributed tracing to follow the flow of requests through complex, microservices-based architectures, enabling teams to pinpoint bottlenecks and latency issues.
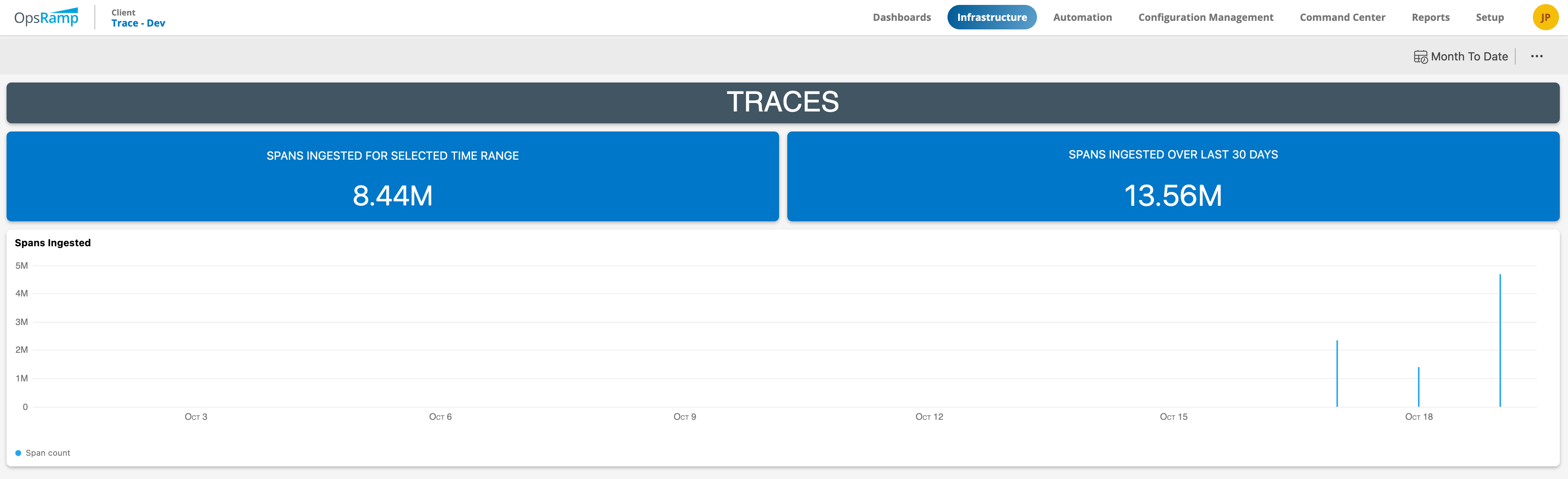 Figure 3: Distributed tracing in OpsRamp
Figure 3: Distributed tracing in OpsRamp
Alerting and Notifications: Setting up alerts and notifications to proactively detect and respond to anomalies and critical incidents and events in the cloud environment.
Cost Monitoring: Tracking cloud spending and resource usage to optimize costs and prevent unexpected expenses and cost overruns.
Cloud-Native Observability
Cloud-native observability takes the concept of observability a step further, specifically focusing on applications and services built using cloud-native technologies and best practices. Cloud-native applications are typically containerized, orchestrated with platforms like Kubernetes, and designed to be highly scalable and resilient.
Key elements of cloud-native observability include:
Container Orchestration Metrics: Monitoring containerized applications and their orchestration platforms, such as Kubernetes, to ensure efficient resource utilization and to be able to dynamically scale applications as needed.
Service Mesh Observability: Tracking the communication between microservices within a service mesh, which is common in cloud-native architectures, to understand how services interact and to be able to quickly identify potential issues.
Auto-scaling Metrics: Monitoring auto-scaling events in order to adapt to changing workloads dynamically.
Application Performance Monitoring (APM): Gaining deep insights into application code and performance, including transaction tracing and code profiling.
Infrastructure as Code (IaC): Observing changes in infrastructure provisioning and configuration using IaC tools like Terraform or AWS CloudFormation.
Why Cloud and Cloud-Native Observability Matter
Cloud and cloud-native observability are becoming increasingly important because they help enable IT, DevOps and CloudOps teams to achieve several business-critical objectives including:
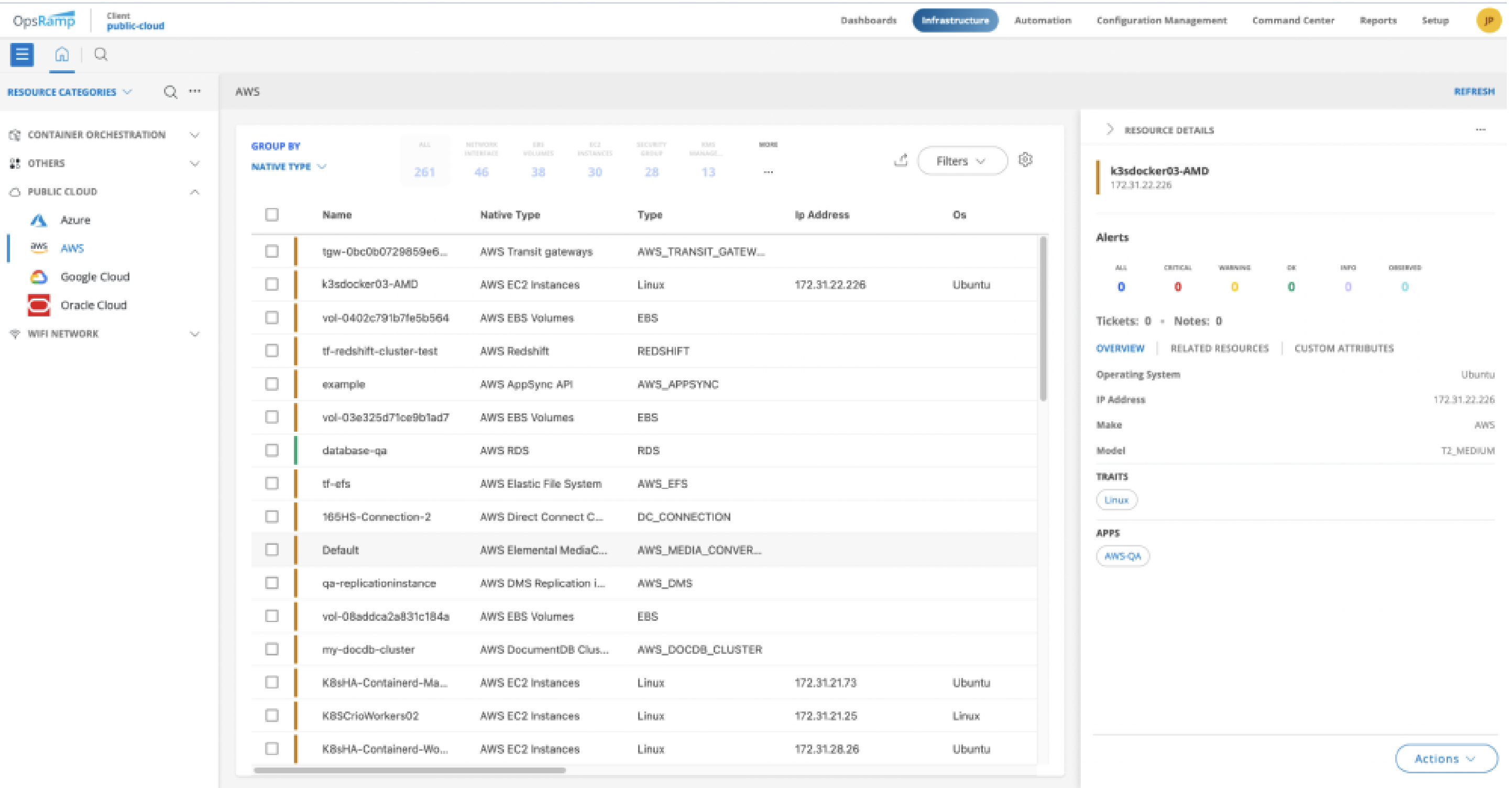 Figure 4: Cloud and cloud-native management in OpsRamp
Figure 4: Cloud and cloud-native management in OpsRamp
Ensuring Reliability: By gaining real-time insights into applications and infrastructure, teams can proactively identify and mitigate issues, ensuring that business-critical services remain up and reliable.
Optimizing Performance: Observability data helps optimize resource allocation, reduce bottlenecks, and improve application performance, leading to a better user experience.
Reducing Downtime: Rapid identification and resolution of issues minimize downtime and performance degradations.
Enhancing Security: Detecting unusual behavior and potential security threats through observability tools can help strengthen the security posture of cloud and cloud-native applications and services.
Conclusion
In the brave new world of cloud computing and cloud-native development, observability is increasingly becoming a necessity, not a nice-to-have. Traditional monitoring approaches and tools often fall short in these new complex, ephemeral and dynamic environments, making cloud and cloud-native observability practices vital for maintaining the performance, reliability, and security of modern applications and infrastructure. Embracing these new observability practices and approaches is key to surviving and thriving in the fast-paced, ever-changing world of digital transformation and technology.
To learn how the OpsRamp platform provides cloud and cloud-native observability, please visit: https://www.opsramp.com/solutions/hybrid-observability/
Next Steps:
- Read the blog: How OpsRamp Closes the Complexity Gap with Distributed Tracing
- Read the blog: How OpsRamp Log Management Helps You to Find and Fix Issues Faster
- Read the OpsRamp Trace Management Data Sheet.
- Learn more about full stack observability at OpsRamp



