


Are outages an unavoidable part of IT operations? Going by the disruptions we’ve seen this year, the answer seems to be a resounding yes. Here are three incidents that hit the headlines in the second quarter of 2018:
- In April, UK’s TSB bank suffered a crippling outage that lasted for two weeks and left nearly 2 million customers stranded. The bank’s CEO, Paul Pester, will lose millions in annual bonuses and the bank will have to pay huge damages to customers.
- In May, Australia’s largest telecom provider, Telstra, experienced a major nationwide outage, that kept subscribers without access to voice and data services for hours. After the outage, the company’s stock price dropped to its lowest levels since 1999.
- In June, messaging app Slack suffered an outage that lasted for nearly four hours and affected millions of users. In 2018 alone, Slack has seen five disruptions to its service.
While there’s no predicting when an IT outage will hit, how you respond to the outage is well within your control. Do you have a well-established framework for handling IT incidents? Or, do your response teams react slowly to a critical emergency and waste time in unproductive discussions? A swift and coordinated incident response drives faster recovery, maintains customer trust, and avoids costly financial and reputational damages.
Incident Management System (IMS): A Survival Manual For The Fire Department
Have you ever wondered how firefighters handle large-scale emergencies where a few seconds of delay can result in the loss of life and property? What valuable lessons can IT teams learn from fire departments about incident management? To answer these questions, veteran firefighters, Rob Schnepp, Ron Vidal, and Chris Hawley wrote Incident Management for Operations, to explain how the fire service “manages time-sensitive incidents in which the stakes are high, the decision making environment is poor, the conditions are changing, and the outcomes are uncertain.”
Fire service departments have long used the Incident Management System (IMS) to handle all kinds of incidents, from everyday fires to major emergencies. The IMS offers a common language for incident response, so that fire departments can respond in a predictable and efficient manner to all-hazard, all-risk events.
With outages costing organizations $700 billion per year, enterprises need the right ‘leadership, collaboration, and shared working patterns’ for addressing high severity IT incidents. Here are three best practices from the book for building the right incident response patterns and habits in your organization.
Practice #1 - Establish A PROCESS For Incident Response
If you’re looking to resolve incidents as quickly as possible, your IT operations team needs a shared understanding of what it takes to manage an incident effectively. You should first evaluate your current incident response process to learn what you’re doing well and what you’ll need to change.
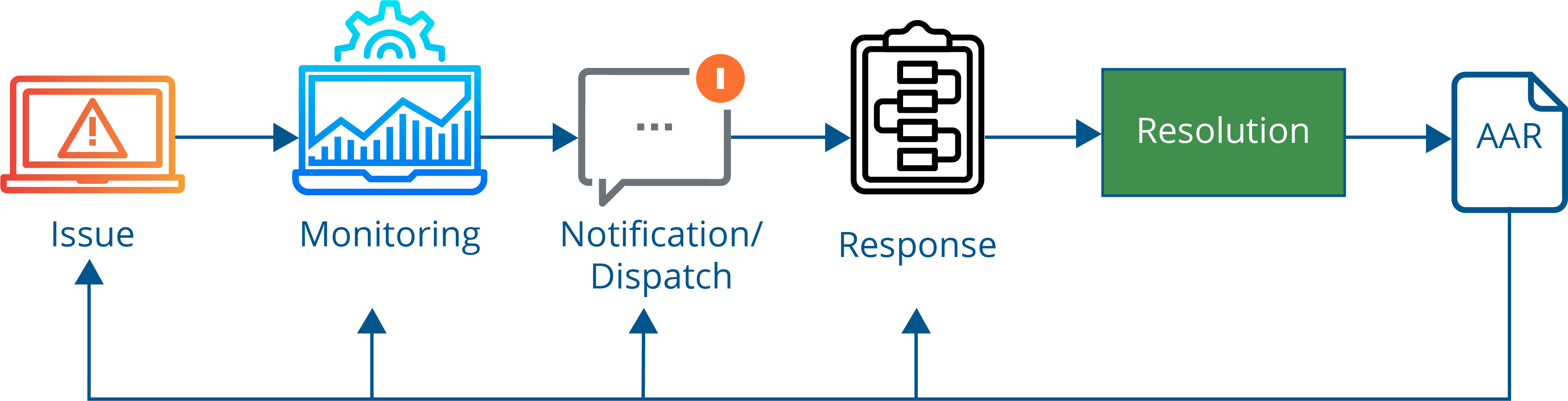
Figure 1 - Establish a robust PROCESS to manage your incident lifecycle (Source: Incident Management for Operations).
As outlined in the book, the acronym PROCESS lays out seven attributes that you need for a productive incident response program:
- Predictable - Are your incident responders clear about their role and responsibilities? Do they know who’s on-call and who’s available as a backup during an emergency?
- Repeatable - Can you assemble the right experts at short notice for an incident? Will your teams respond consistently no matter what time of day or day of the week it is?
- Optimized - Are your responders properly trained and equipped to contribute effectively during an outage? Are there clear rules of engagement, formal training programs, and defined SLAs for incident response?
- Clear - Are individuals clear about why they are needed and the role they will play in an incident? Do they share the same viewpoints and have unity of purpose for handling an outage?
- Evaluated - Are you able to identify areas of improvement and take corrective measures to improve deficiencies? Do you review each area of your incident lifecycle to drive faster response the next time around?
- Scalable - Have you assembled the right experts for different types of incidents? Can you stop relying on the same individuals to prevent burnout by offering adequate rotation between incidents?
- Sustainable - Are you able to shortlist the right individuals for working on incident management? Do you have proper incentives in place to attract and retain great talent?
Practice #2 - Incident Management Is A Wartime Activity
Downtime can negatively affect your company’s bottom line and reputation. Research firm Aberdeen estimates that the average cost of downtime per hour is $163,674. When you face a critical incident, shift to wartime mode to maximize uptime and restore operations back to normal.
To resolve incidents with maximum efficiency and minimum time, you need the following three ingredients:
 Figure 2 - Resolve incidents effectively with the right set of ingredients (Source: Incident Management for Operations).
Figure 2 - Resolve incidents effectively with the right set of ingredients (Source: Incident Management for Operations).
To address wartime incidents, use the Incident Management System to organize the right subject matter experts under the leadership of an Incident Commander in a timely manner. You’ll be able to establish an effective incident response process that’ll help protect your company’s reputation, market standing, and financial position.
Practice #3 - Control The Chaos With An Incident Commander
Given that incident management is a people-to-people activity, you’ll need an Incident Commander who creates an overall action plan, works with SMEs to figure out the right tactics for resolution and keeps the broader team informed on the incident timeline.
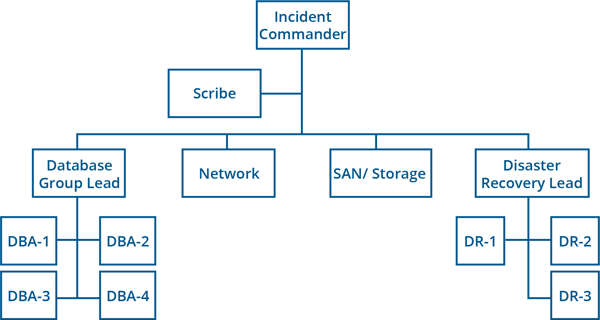 Figure 3 - The Incident Commander handles response with the right team of experts (Source: Incident Management for Operations).
Figure 3 - The Incident Commander handles response with the right team of experts (Source: Incident Management for Operations).
So, what does an Incident Commander actually do? An Incident Commander manages the incident lifecycle by “summarizing, consolidating, and ensuring understanding across the entire group of incident responders.” The Incident Commander doesn’t directly work on the issue but organizes and leads a team of domain experts to manage the response. It’s the commander’s job to foster careful and considered discussions among SMEs and create the right plan of attack for troubleshooting and service restoration.
Conclusion
Does your team descend into chaos when confronted with a high severity incident? Do you have heated and contentious debates during an outage (or do cooler heads prevail)? If you’re looking to manage major incidents without stress, definitely check out Incident Management for Operations to learn how fire service departments manage response across a wide variety of situations.



