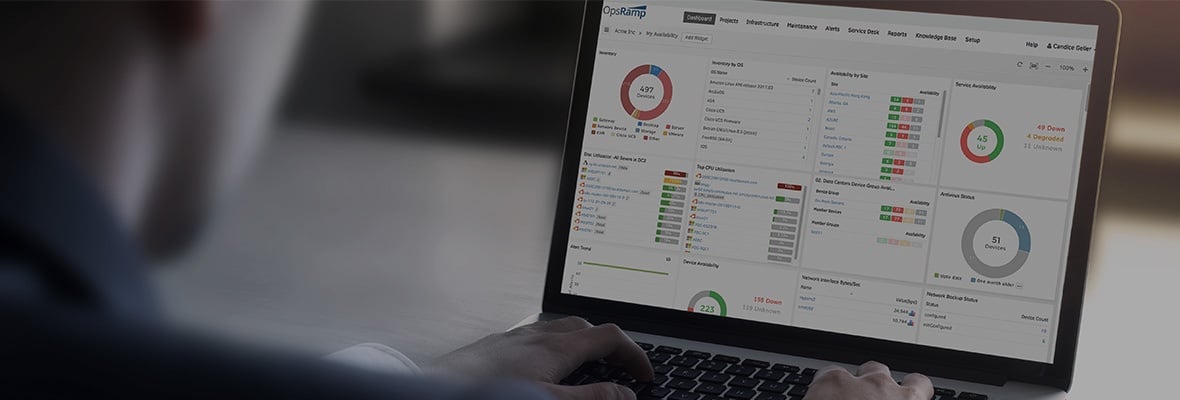
記事上で:
- OpsRampの機械学習の方法(OpsQ) ITチームがインシデントを処理して、より正確な優先順位付け、ルーティング、および割り当てを可能にする方法を学ぶことができます。
- インテリジェントアラートエスカレーションの3つのコンポーネントについて学ぶ;
- ITSMがアラートエスカレーションの意思決定ツリーの構築を開始するためのシードとなる方法.
アプリケーション、クラウド環境、およびポイント監視ツールの増加を考えると、アラート管理はもはや管理可能なタスクではありません。アラートデータのフィルタリングと理解、およびインシデントのルーティング先の決定に多くの時間が費やされています。これらの手順はすべて、重大な問題の特定と解決を遅らせます。
この記事では、機械学習インテリジェンスと自動化を通じて、ITアラートを処理するためのより賢明で最新の方法について説明したいと思います。インテリジェントアラートエスカレーションの概念は、 AIOps アラート管理から非効率的な手作業を取り除き、オペレーターがビジネスの重要な問題の調査と修正に遅滞なく集中できるようにするテクノロジー.
Iインテリジェントアラートエスカレーションには、次の5つのアクティビティが組み込まれています。:
- アラート/インシデントルーティングの一連のポリシーを作成する;
- インシデント作成の条件を定義する;
- ITサービス管理プラットフォームと統合する;
- OpsRampで継続的な学習を有効にして、意思決定ツリーモデルをトレーニングします;
- 未知のイベントの解決にスタッフのワークフローを再集中させる.
OpsRampを使用したインテリジェントなアラートエスカレーションは、次の利点を提供できます:
- 方向性を求めてイベントストリームの画面を見つめるチームはもうありません;
- 新しいインシデントに焦点を合わせるためにワークフローをシフトする;
- 機械学習(OpsQ)を使用して、チームがインシデントを処理する方法を学習し、より正確な自動化を可能にします。
- 調査と解決を改善するための充実したインシデントの提供;
- 時間を節約するためのITサービス管理(ITSM)ツールとの統合。
- より良いビジネスの対応と調整。
入門 入門
- 適切なポリシーを選択します。 ほとんどの組織にはアラートエスカレーションポリシーがありますが、ポリシーが多すぎるか、優先度が高くない場合があります。ビジネスサービスの最大のリスクに関連する、5つまたは6つ以下の重要なアラートエスカレーションポリシーをいくつか作成することから始めます。.
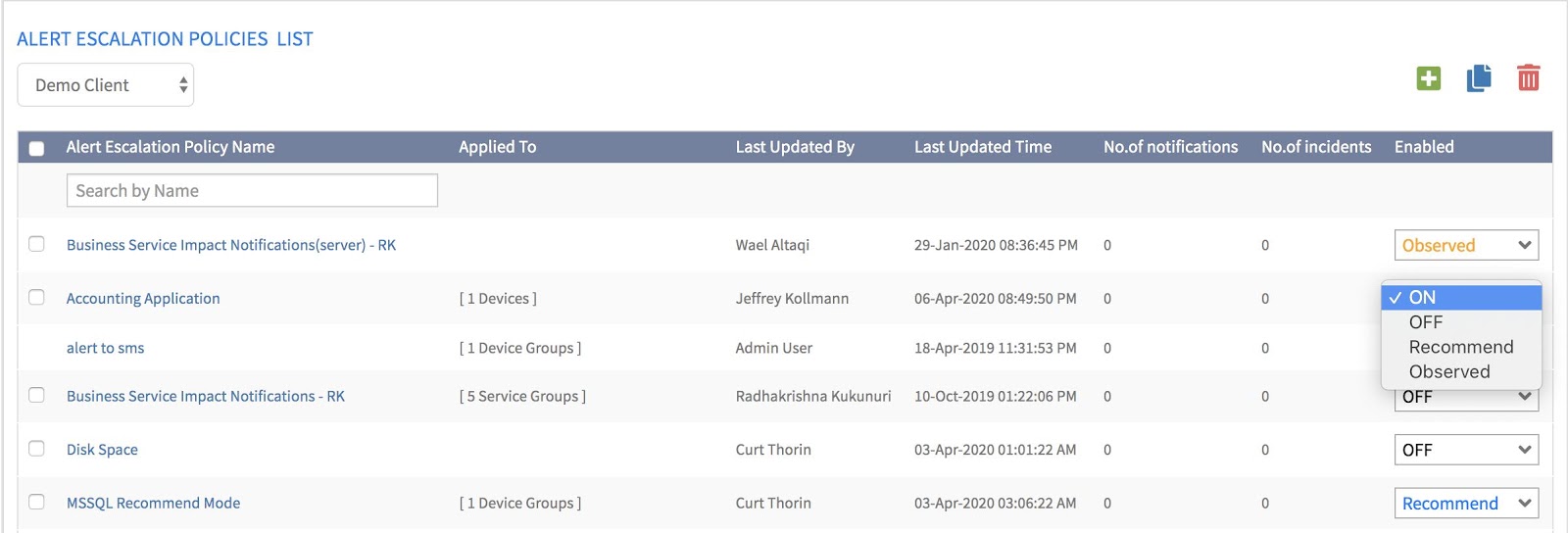
- アラートからインシデントを作成するための条件を定義します。 OpsRamp機械学習アルゴリズムは、そこからプロセスを推進し、適切なオペレーターにアラートを送信します。オペレーターは、タグでインシデントを強化し、適切なインシデント解決ワークフローを開始できます。 OpsRampには完全な名簿サポートが含まれているため、アラートを現在勤務中の人にルーティングできるため、時間のかかるテキストや電話で利用可能な専門家を探す必要がなくなります。. Note: このプロセスは、OpsRampがアラートを自動的に重複排除、フィルタリング、相関させてノイズを低減した後に行われます。通常、組織では、このプロセスを通じてアラートの量が60〜80%減少します。
- Integrate with ITSM. OpsRampは提供しますout-of-the-box ServiceNow やその他の一般的なITSMツールとの統合。当社のAPIを使用すると、ITチームはプラットフォームを他の選択したITSMに接続することもできます。まず、コンテキスト用にITSMシステムから履歴チケットデータをインポートできます。これは、アラートのエスカレーション、優先順位付け、およびルーティングのための意思決定ツリーの構築を開始するためのシードです。この統合により、ユーザーはサービスデスクシステムと ITインシデント管理システム. インシデントはOpsRampで作成し、ITSMツールでチケットとして自動的に入力できます。インシデントワークフロープロセスの各ステップで、ITSMシステムは最新の情報とステータスで自動的に更新されます。そうすれば、デスクの従業員を助ける, IT運用 スタッフとSREを同じページに配置できます。また、これは双方向の統合であるため、情報の流れは双方向になり、OpsQはITSMシステム内で実行されたアクションから学習できます。
- 有効 継続学習 アラートとインシデントの管理を改善する. OpsRampのアラートエスカレーションおよびルーティング機能の使用を開始すると、システムはベストプラクティスを学習し、後でそれらをエミュレートできます。これにより、特に一般的な繰り返し可能なイベントで、多くの時間と労力を節約できます。これがどのように機能するかを説明するために、最初にイベント管理チームにルーティングされ、次にネットワークレベルIの優先順位が割り当てられるチケットについて考えてみます。調査後、そのチームはインシデントをSQL DBA L2チームに割り当てることを決定し、SQL DBAL2チームはチケットを高優先度に変更します。次回同様のインシデントが作成されると、DBAチームに直接ルーティングされ、適切なナレッジドキュメントが添付されます。これにより、既知のイベントのトリアージの時間をバイパスできます.
トレーニングを開始するには、OpsRampのアラートエスカレーションポリシーで継続学習を有効にする必要があります。トレーニングファイルを準備し、インシデントの決定を推進するために使用される属性(リソースグループ、クラウドサブスクリプション、カスタム属性など)を記録できます。列名のみを含む空のCSVファイルを提供することにより、OpsQに既存のアラートおよびインシデントデータからフィールド値を学習させることもできます。 OpsQは、過去3か月のアラートおよびインシデントデータからインシデント作成ルールを学習します。学習プロセスは毎月実行され、学習されたMLモデルがデータの最新のパターンと一致することを確認します。 - スタッフの時間を未知のイベントに集中させます。 インシデントを作成し、既知の結果が得られないイベントが発生すると、ITSMの一般インシデントキューにルーティングされます。次に、イベント管理チームがインシデントを割り当て、優先順位を付け、ルーティングします。これにより、OpsRamp内の学習プロセスが促進されます。これにより、専門家はより困難でより曖昧な問題にエネルギーを集中させることができます。
OpsRampについて詳しく知ることができます 観察 と おすすめモード スマートで安全な自動化の道筋をユーザーに案内します。
関連リンク:
- TechTalk: OpsRampのインテリジェントエスカレーションがリモートワーカーを可能にする方法
- Blog: アラートの統合:適切な人、適切なメッセージ、適切なタイミング
- Blog: ポリシーベースのアラートエスカレーション管理により、インシデントのダウンタイムを削減し、停止をより早く修正します