従来のエンタープライズアプリケーションプラットフォームは通常、Java Enterpriseテクノロジーで構築されており、これはOpsRampにも当てはまります。ただし、機械学習(ML)の世界では、Pythonが最も一般的に使用される言語であり、Javaはめったに使用されません。次のようなエンタープライズプラットフォーム内でMLコンポーネントを開発するため AIOps機能 in OpsRamp、MLコンポーネントをPythonマイクロサービスとして実行する必要があり、それらはプラットフォーム内のJavaマイクロサービスと通信します。
JavaプロセスとPythonプロセスを接続するために使用しますプロセス間通信(IPC)。 IPCは、プロセスが相互に通信し、それらのアクションを同期できるようにするメカニズムです。この場合、「メッセージパッシング」メソッド IPCメッセージパッシングの基盤となるテクノロジーとしてKafkaデータパイプラインを使用して、JavaプロセスとPythonプロセスを同期します。
MLクラスターの配置図は、使用方法を示しています Kafkaデータパイプライン MLジョブリクエストを保存してディスパッチします。 Kafkaデータパイプラインを使用すると、機械学習コンポーネントはフォールトトレラントになります。すべての機械学習ノードがダウンした場合でも、未処理のリクエストは、Kafkaトピック「ml.pipeline.input」にメッセージとして保存されるため、安全です。 MLノードが再びオンになると、ノードは未処理のリクエストの処理を続行できます。
MLクラスターに複数のノードがある場合、この設計により、負荷を増やすためのスケールアウトが保証され、ローリングアップグレードのためのノードのダウンタイムがなくなります。
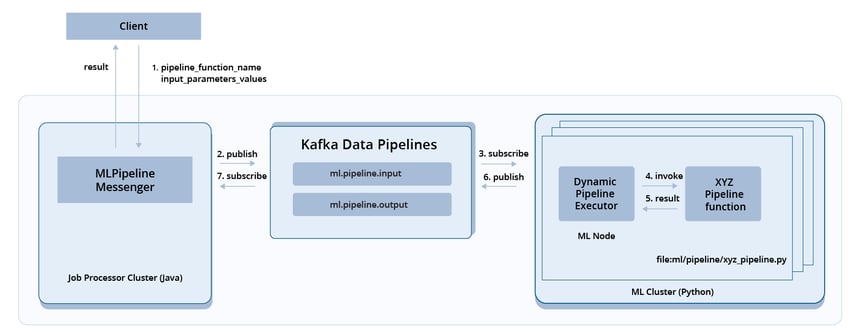 機械学習実行のためのKafkaデータパイプライン。
機械学習実行のためのKafkaデータパイプライン。
拡張可能なMLアプリケーションプラットフォームの構築
で説明されているように 以前のブログ、機械学習コンポーネントは、OpsRampプラットフォームのパイプラインとしてデプロイされます。パイプラインには、トレーニングパイプラインと推論パイプラインの2種類があります。トレーニングパイプラインは機械学習モデルを作成し、推論パイプラインはトレーニングされたモデルを使用して予測を提供します。
既存のエンタープライズアプリケーションプラットフォームのもう1つの問題は、カスタマイズされたユースケースをサポートするために、顧客が独自の機械学習パイプラインを定義したいということです。プラットフォームは、これらのパイプラインを呼び出すための拡張可能でメンテナンスフリーの方法を見つける必要があります。
私たちのソリューションは動的パイプライン呼び出し.
上記の配置図に示されているように、ステップ1で、クライアントはプラットフォームに要求を送信します。リクエストには、パイプライン関数名と関数の入力パラメーター値が含まれています。リクエストは、メッセージとしてKafkaトピック「ml.pipeline.input」に配置されます。手順3で、メッセージはMLクラスター内のノードによって取得されます。手順4では、MLノードのパイプラインエグゼキュータがメッセージを使用してパイプライン関数を式として作成します。次に、パイプラインエグゼキュータはPythonの「eval」関数を使用して、要求されたパイプライン関数を動的に呼び出します。
結論
エンタープライズSaaSプラットフォームには、数百万の同時ユーザーがいる可能性があります。プラットフォームの機械学習ソリューションは、スケーラブルで、フォールトトレラントで、拡張可能である必要があります。既存のプラットフォームテクノロジーとうまく連携する必要があります。機械学習アプリケーションプラットフォームでKafkaデータパイプラインを使用し、動的MLパイプラインを実行するという私たちのアプローチにより、SaaSプラットフォームで企業のお客様を今後何年にもわたってサポートすることができます。また、AIOpsスペースでの継続的な成長を促進します。
次のステップ:
- 詳細については OpsRampサービス中心のAIOps プロアクティブなIT運用のために。
- OpsRampをフォローする ツイッターと LinkedInIT運用の世界からのリアルタイムの更新とニュース。
- カスタムデモをスケジュールする OpsRampソリューションの専門家と。