


Traditional enterprise application platforms are usually built with Java Enterprise technologies and this is the case as well for OpsRamp. However, in machine learning (ML) world, Python is the most commonly used language, with Java rarely used. To develop ML components within enterprise platforms, such as the AIOps capabilities in OpsRamp, we have to run ML components as Python microservices and they communicate with Java microservices in the platform.
To connect the Java process and the Python process we use inter-process communication (IPC). IPC is a mechanism that allows processes to communicate with each other and synchronize their actions. In this case, we used the “Message Passing” method to synchronize Java and Python processes, with Kafka data pipelines as the underlying technology for IPC message passing.
The deployment diagram of ML cluster shows how we use Kafka data pipelines to store and dispatch ML job requests. With Kafka data pipelines, the machine learning components are fault-tolerant. Even if all the machine learning nodes go down, the unprocessed requests are safe as they get stored as messages in the Kafka topic: “ml.pipeline.input”. Once the ML nodes come back on, nodes can continue handling unprocessed requests.
When the ML cluster has multiple nodes, this design also ensures scale-out for increased load and no downtime on nodes for rolling upgrades.
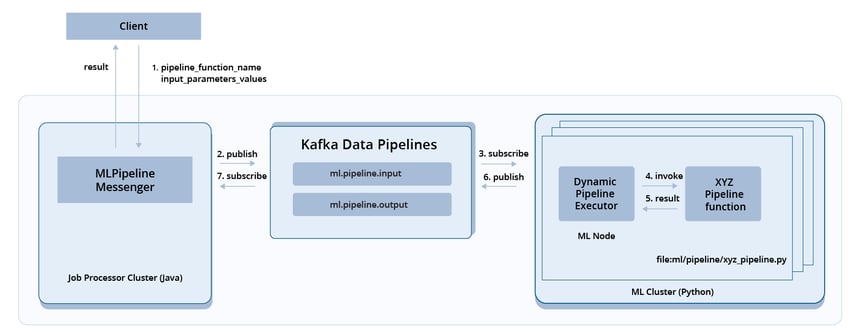 Kafka Data Pipelines for Machine Learning Execution.
Kafka Data Pipelines for Machine Learning Execution.
Building an Extensible ML Application Platform
As described in an earlier blog, machine learning components get deployed as pipelines in the OpsRamp platform. There are two types of pipelines: training pipelines and inference pipelines. A training pipeline creates a machine learning model while the inference pipeline uses the trained model to deliver predictions.
Another problem with existing enterprise application platforms is that customers would like to define their own machine learning pipelines to support customized use cases. The platform has to find an extensible and maintenance-free way to invoke those pipelines.
Our solution is Dynamic Pipeline Invocation.
As illustrated in the above deployment diagram, in Step 1, the client sends the platform a request. The request has the pipeline function name and the input parameter values of the function. The request gets placed in the Kafka Topic, “ml.pipeline.input”, as a message. In step 3, the message gets picked up by a node in the ML cluster. In step 4, the pipeline executor of the ML node builds out the pipeline function as an expression using the message. The pipeline executor then uses the Python “eval” function to dynamically invoke the requested pipeline function.
Conclusion
An enterprise SaaS platform can have millions of concurrent users. The machine learning solution in the platform must be scalable, fault-tolerant, and extensible. It must play well with the existing platform technologies. Our approach of using Kafka data pipelines in the machine learning application platform and dynamic ML pipeline execution enables us to support enterprise customers in a SaaS platform, for many years to come. It also furthers our continued growth in the AIOps space.
Next Steps:
- Learn more about OpsRamp service-centric AIOps for proactive IT operations.
- Follow OpsRamp on Twitter and LinkedIn for real-time updates and news from the world of IT operations.
- Schedule a custom demo with an OpsRamp solution expert.



