

ビジネス向けの機械学習と消費者向けの機械学習の違いは、ビジネスアプリケーションの場合、カジュアルユーザーが遭遇しない要件に対処する必要があることです。
の必要性 「下位互換性のある」モデル
ビジネスグレードの機械学習モデルを構築する人は誰でも、モデルが壊れやすいことを直接目にしました。モデルはトレーニングデータとトレーニングコードを使用して作成されます。トレーニングコードを変更すると、既存のデプロイ済みモデルに互換性がなくなり、使用できなくなる可能性があります。一般に、各顧客には、独自のデータパターンをキャプチャするための独自のモデルがあります。つまり、操作では、既存のトレーニング済みモデルを新しくトレーニング済みのモデルに置き換える必要があります。そうしないと、既存のモデルを使用した予測でエラーが発生します。 MLモデルの再トレーニングは、コストと時間のかかるプロセスです。
さらに悪いことに、トレーニングコードはリリースごとに変更されます。これは、機械学習エンジニアの仕事がモデルトレーニングを改善し、リリースごとにモデルをより正確にすることであるためです。 したがって、「下位互換性のあるモデル」をサポートすることがビジネスにとって最も重要です。これは、以前のリリースで作成されたモデルとして定義され、モデルが新しいデータと新しいコードで再トレーニングされるまで、新しいリリースで引き続き使用できます。
下位互換性をサポートするための明白な選択はバージョン管理ですが、古いコードと新しいコードを明確に区別できるバージョンを使用するにはどうすればよいですか?従来のif / elseアプローチは、エラーが発生しやすいため、オプションではありません。
OpsRampでは、シンプルで効果的な機械学習バージョン管理アプローチを開発しました。これは、下位互換性のあるモデルのnバージョンをサポートするように簡単に拡張できます。このソリューションは、生産製品の機械学習の構築に真剣に取り組んでいる他の人にも役立つと信じています。
機械学習パイプライン
バージョニングに入る前に、「機械学習パイプライン」の概念について簡単に説明します。これは、機械学習プロセスをモデル化するアーキテクチャパターンです。各MLパイプラインには、データの取得、データの変換、モデルのトレーニング、モデルの保存など、複数のステップが含まれています。
パイプラインには、トレーニングパイプラインと推論パイプラインの2つの基本的なタイプがあります。トレーニングパイプラインは機械学習モデルを作成し、推論パイプラインはトレーニングされたモデルを使用して予測を行います。これらの2つのパイプラインは、ペアとして連携して機能します。
バージョンを機械学習に組み込む方法
バージョン管理をサポートする方法は、トレーニング済みモデルにバージョンを提供することです。推論パイプラインのすべてのバージョン(現在および以前)を機械学習ノードにデプロイします。実行時に、モデルのバージョンと同じバージョンの推論パイプラインがジョブを処理します。他のすべてのパイプラインのバージョンは異なるため、ジョブを無視します。
同じノードで同時に実行されるMLパイプラインの複数のバージョンをサポートするために、 Python仮想環境 推論パイプラインに必要なすべての必要な依存関係を含む分離フォルダーを作成します。
MLノードの配置図は、使用方法を示しています カフカ MLジョブリクエストを処理するためのデータパイプライン。モデルが新たにトレーニングされると、バージョン情報は、Kafkaトピック「ModelCacheEvent」を通じてすべての推論パイプラインにブロードキャストされます。したがって、すべての推論パイプラインはモデルバージョンの知識を更新しました。
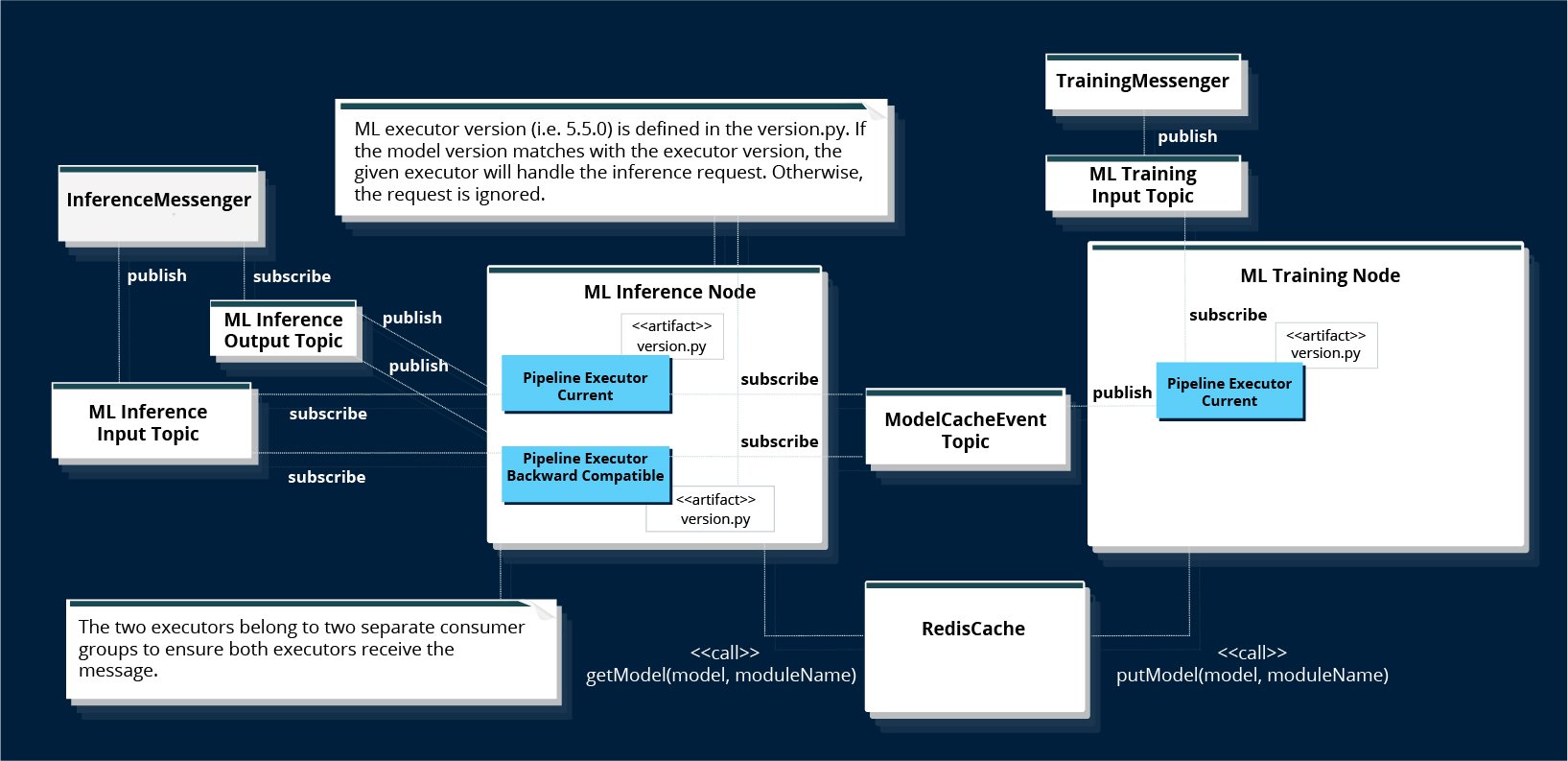 図1.バージョン管理されたMLパイプラインの実行
図1.バージョン管理されたMLパイプラインの実行
従来のif / thenアプローチのバージョン管理と比較すると、この「複数のバージョンを並べて実行する」アプローチははるかに単純であり、デバッグも簡単です。デバッグログは、パイプラインのどのバージョンがジョブを取得するかを明示的に示します。私たちの環境では、すべての推論ログメッセージを単一のログファイルに記録するため、ログを読み、実行フローを簡単にたどることができます。
以下は、ビルド、パッケージ化、および展開プロセスを説明するアクティビティ図です。 PyPiサーバーMLパイプラインパッケージのさまざまなバージョンを保存および管理するために使用されます。 「setup」スクリプトはノード上に仮想環境を作成するために使用され、「run」スクリプトはパイプラインを開始します。
 図2.ナイトリービルドとデプロイのプロセス
図2.ナイトリービルドとデプロイのプロセス
トレーニングノードでは、トレーニングパイプラインの現在のバージョンのみが開始されますが、推論ノードでは、パイプラインの現在のバージョンと1つ前のバージョンが開始されます。生産スケジュールには継続的なトレーニングが組み込まれています。したがって、1つのバージョンの下位互換性で十分ですが、このバージョン管理ソリューションはnバージョンの下位互換性をサポートしています。
機械学習のバージョニングは、機械学習アプリケーションを構築する上で最も難しいタスクの1つです。問題を解決するためのシンプルでエレガントなアプローチを考え出しました。これにより、AIOpsの進行がスピードアップします。
次のステップ:
- IT運用のためのOpsRampの人工知能について学ぶ(AIOps).
- OpsRampをフォローする ツイッター と LinkedIn IT運用の世界からのリアルタイムの更新とニュース。
- カスタムデモをスケジュールする OpsRampソリューションの専門家と。