

The difference between machine learning for business and machine learning for consumers is that for business applications, you must deal with requirements that casual users won’t encounter.
The need for a “backward-compatible” model
Anyone who builds business-grade machine learning models has seen firsthand that the model is fragile. Models are created using training data and training code, and changes in the training code can lead to the existing deployed model becoming incompatible and unusable. Commonly, each customer has its own model to capture its unique data pattern. This means the operation must replace the existing trained model with a newly trained model. Otherwise, predictions using the existing model will lead to errors. Retraining ML models is a costly and time-consuming process.
To make matters worse, the training code changes in every release. This is because the job of machine learning engineers is to improve the model training and make the model more accurate with every release. Therefore, supporting a “backward-compatible model” is paramount for the business. This is defined as a model created in the previous release which can still be used in the new release until the model is retrained with new data and new code.
An obvious choice to support backward compatibility is versioning, but how to use a version that can cleanly separate between the old code and the new code? The traditional if/else approach is not an option since it is too error-prone.
At OpsRamp, we have developed a simple and effective machine learning versioning approach, which can be easily extended to support n-versions of backward-compatible models. We believe this solution will be useful for others who are serious about building machine learning for production products.
Machine learning pipelines
Before we get into the versioning, we'll briefly describe the concept of a “machine learning pipeline.” This is an architecture pattern that models the machine learning process. Each ML pipeline contains multiple steps, such as data retrieval, data transformation, model training, or saving the model.
There are two basic types of pipelines: the training pipeline and the inference pipeline. A training pipeline creates a machine learning model, and the inference pipeline uses the trained model to do predictions. These two pipelines work together as a pair.
How to build versions into machine learning
The way we support versioning is to give the trained model a version. We deploy all versions (current and previous) of inference pipelines on the machine learning node. During runtime, the inference pipeline that is of the same version as the model’s version handles the job. All other pipelines have a different version and hence ignore the job.
To support multiple versions of ML pipelines running at the same time on the same node, we use a Python Virtual Environment to create isolated folders containing all the necessary dependencies needed by the inference pipeline.
The deployment diagram of ML nodes shows how we use Kafka data pipelines to handle ML job requests. Once a model is newly trained, the version information is broadcasted to all inference pipelines through the Kafka topic, “ModelCacheEvent.” Therefore, all inference pipelines have updated knowledge of the model version.
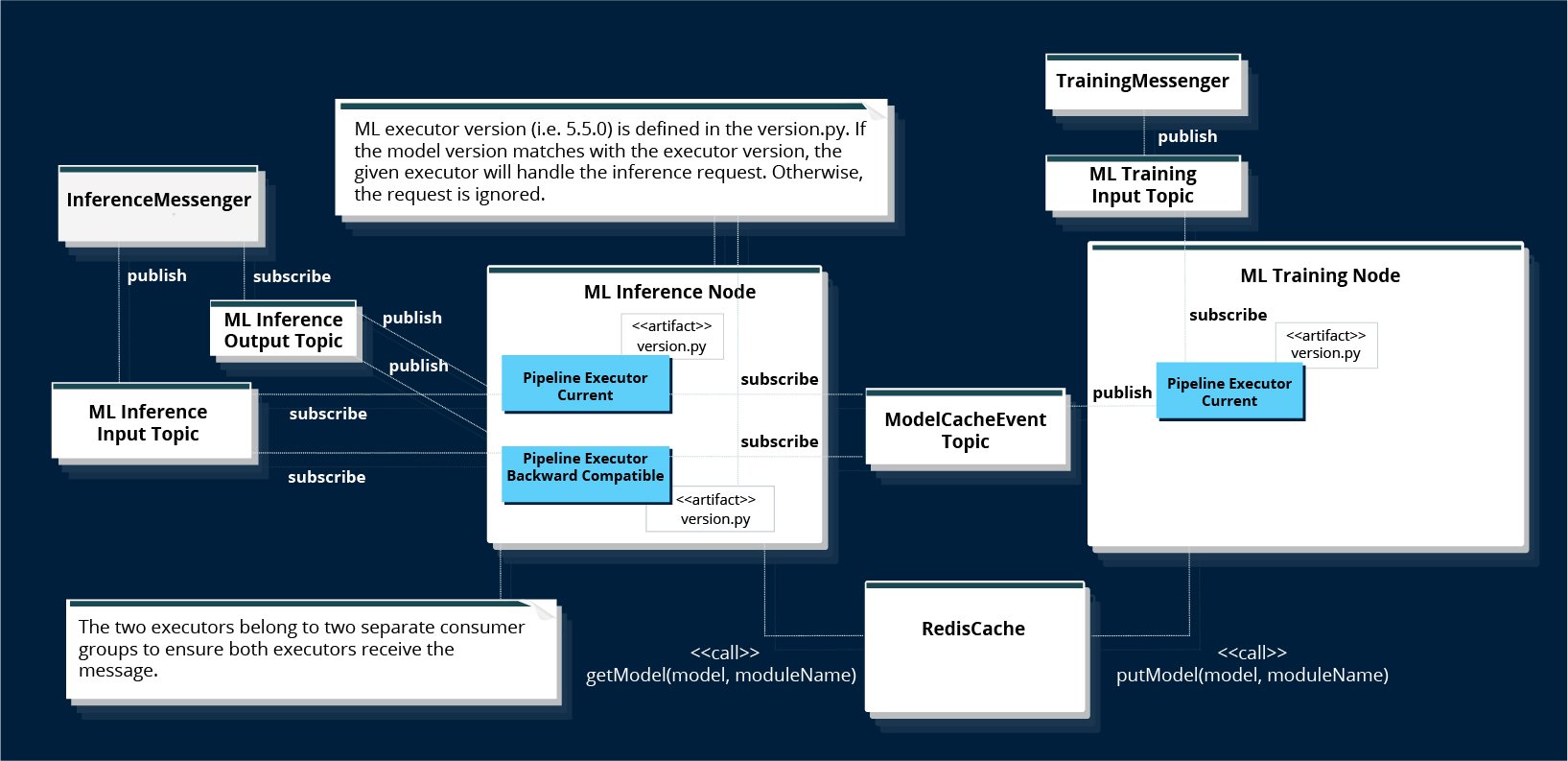 Figure 1. Versioned ML pipeline execution
Figure 1. Versioned ML pipeline execution
Compared to the versioning in the traditional if/then approach, this “multiple versions run side by side” approach is much simpler, and is also easy to debug. The debug log explicitly indicates which version of the pipeline picks up the job. In our environment, we log all inference log messages into a single log file, making it easy to read the log and follow the execution flow.
The following is an activity diagram that describes the build, packaging and deployment process. PyPi Server is used to store and manage different versions of the ML pipeline packages. The “setup” script is used to create the virtual environment on the node, and “run” script starts the pipeline.
 Figure 2. Nightly build and deployment process
Figure 2. Nightly build and deployment process
On the training node, only the current version of the training pipeline is started, but on the inference node, we start current version and one previous version of the pipeline. We have continuous training built into the production schedule. Therefore, one version backwards is sufficient for us, but this versioning solution supports n versions of backwards compatibility.
Machine learning versioning is one of the most challenging tasks in building machine learning applications. We figured out a simple and elegant approach to solve the problem, and it speeds up our AIOps progress.
Next Steps:
- Learn about OpsRamp’s artificial intelligence for IT operations (AIOps).
- Follow OpsRamp on Twitter and LinkedIn for real-time updates and news from the world of IT operations.
- Schedule a custom demo with an OpsRamp solution expert.



