あなたの仕事が管理を伴うときIT運用プラットフォーム OpsRampのように、あなたは独特の課題に直面します。何千もの顧客が、ビジネスクリティカルなアプリとインフラストラクチャを管理するためにOpsRampに依存しています。毎日、プラットフォームで新しいデバイス、インフラストラクチャサービス、ITツールを管理しています。そして、99.99%のサービスレベルの可用性を維持しながらこれを行う必要があります。
ハイパースケールSaaS運用の秘訣は何ですか?まあ、それは簡単です。 OpsRampプラットフォームを使用して、北米、ヨーロッパ、および日本全体で独自のSaaS規模の運用を管理しています。
SaaS Opsチームは、プラットフォームのスケーラビリティ、信頼性、セキュリティをどのように推進していますか? OpsRampは、ダッシュボード、ポリシー、サービスデスク、ナレッジベース、および統合を使用して、SaaSプラットフォームの可用性とパフォーマンスを保証します。
カスタムダッシュボード
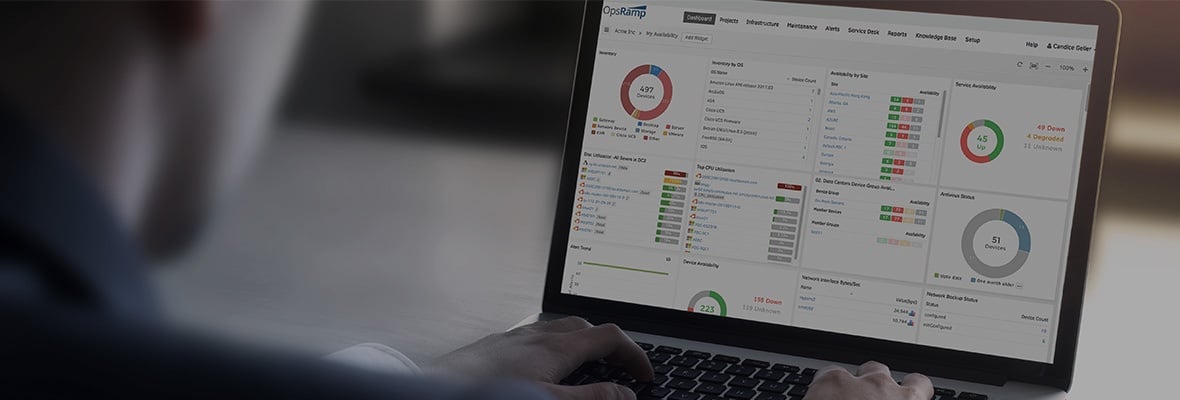
ダッシュボードには、SaaSプラットフォームがいつでもどのように機能するかが表示されます。 SaaS Opsチームは、プラットフォーム全体の状態を理解するためにさまざまなダッシュボードを設定します。たとえば、米国の地域ダッシュボードには、デバイス数、サービスの可用性、およびデバイスのパフォーマンスが表示されます。
 図1-米国地域のダッシュボード
図1-米国地域のダッシュボード
地域およびサービスレベルのダッシュボードは、プラットフォームの稼働時間を管理するのに役立ちます とパフォーマンス。ダッシュボードは、アプリケーションだけでなく、API、ビッグデータクラスター、さらにはアラートやチケットも監視します。私たち 関連する追跡により、重要なサービスの可用性を管理します デバイス、メモリ、およびCPU使用率のメトリック。

図2 -ビッグデータクラスター ダッシュボード
ビッグデータダッシュボードは、ビッグデータクラスター(Cassandra、Kafka、Hadoop)の読み取りおよび書き込み要求の待機時間、メモリ使用量、圧縮保留タスク、および上位のCPU使用率デバイスを追跡します。
デバイスグループ
SaaSインフラストラクチャを ポリシーとフィルターを使用するデバイスグループ。各デバイスグループのパフォーマンスは、 ダッシュボード。新しいデバイスが搭載されると、ダッシュボードは最新のインフラストラクチャを反映するように自動的に更新されます。ポリシーベースのデバイス管理により、プラットフォームが最新であり、常に管理されていることが保証されます。

図3 - デバイスグループ
ディスカバリーポリシー
OpsRampの検出プロファイルは、世界中の場所にあるデバイスに迅速に搭載されます。サーバー、アプリノード、サブネット、メトリクスプロセッサの検出プロファイルがあります。私たち 全体でデータを収集するための検出プロファイルのスケジュールを定義する 定期的にさまざまなデバイス。
OpsRampは、ゲートウェイとエージェントを使用してデバイスデータを検出します。ゲートウェイはハイパーバイザーとネットワーク情報を収集し、エージェントはオペレーティングシステムのメトリックを収集します。

図4 - 発見 & 展開ポリシー
デバイス管理ポリシー
デバイス管理ポリシーは、デバイスを監視する方法を定義します。デバイス管理ポリシーは、監視テンプレート、ナレッジベースの記事、およびカスタム属性を検出されたデバイスに適用します。
デバイス管理ポリシーは、新しいデバイスが追加されるたびにトリガーされます。 OpsRampの監視テンプレートは、ライフサイクル全体で新しいデバイスを自動的に管理します。

図5 - デバイス管理ポリシー
アラート管理
[アラート]タブは、関連するアラートをグループ化し、チケットまたは変更要求を作成して、解決を通じて問題を管理します。私たち アラートを手動で作成します。チームはアラートを処理してチケットを作成します。私たち また、人間の介入なしに自動インシデントポリシーを使用してアラートを作成します。自動インシデントポリシーは、クリティカルアラートのチケットを作成し、チケットをSlackワークフローに統合します。

図6 - アラートブラウザ
サービスデスク
サービスデスクは、プラットフォームのサービスリクエストの管理に役立ちます。各チケットの会話、アクティビティログ、記録、メモ、ステータス、アラートを追跡します。サービスデスクは、すべてのSaaS運用を保証します 監査可能で追跡可能です。

図7 - サービスデスク
知識ベース
プラットフォームのメンテナンスのためのアクティブな知識ベースを維持しています。構成、データ管理、展開、標準の操作手順、およびトラブルシューティングのためにナレッジベースの記事を分離します。
チケットやデバイスに記事を割り当てて、 チームは問題に迅速に対応して解決します。また、検索可能なナレッジベースの記事を使用して、スタッフのトレーニング時間を短縮することもできます。

図8 - 知識ベース
統合
スラック
たるみは 内部コラボレーションツール Opsチームのために。 Slackとの統合により、指定されたSlackチャネル内のチケットを表示、アドレス指定、解決できます。 Slackは、アプリケーションとインフラストラクチャのパフォーマンスを常に把握するのに役立ちます プラットフォーム。

図9 - Slackインシデント管理チャネル
Jenkins
すべてのビルド展開にJenkinsを使用しています。 Jenkinsの統合により、リリースサイクル中にコードベースを構築してテストできます。ビルドをデプロイする必要がある場合、自動トリガーするようにJenkinsジョブを構成します OpsRampのアラート。