


In 2020, the concept of observability in IT operations gained mindshare as IT leaders looked for new ways to rein in the complexity that’s grown organically with cloud computing and rapid digitization.
Observability differs from IT monitoring in that it focuses on the development of the application and rich instrumentation so that operators can ask meaningful questions about how the software works or is working in production. The ability to ask new questions allows IT to gain different perspectives on application behavior so that they can optimize and improve results for customers.
Another way to think about observability is that it’s all about the user perspective, which requires a user-centric mindset and approach. While traditional (black box) monitoring provides metrics that indicate whether a system is up and running or not, observability takes this a step further by showing if it’s actually performing adequately for business and user requirements.
While traditional (black box) monitoring provides metrics that indicate whether a system is up and running or not, observability takes this a step further by showing if it’s actually performing adequately for business and user requirements."
Observability in Action
Observability creates sharper connections to the business value of infrastructure monitoring by solving issues such as:
- A server’s online and available, but the applications it supports are malfunctioning;
- The network’s up but a user's transactions may not be going through or the website is behaving erratically;
- Your site is working fine in one browser but not in another.
These are the kind of problems that IT organizations need to know about pronto before users start to complain or leave your site/app for the better performing service. That’s terrible for customer retention and for employees, it may result in costly, insecure shadow IT.
Either way, a lack of observability means that your organization is more prone to low user satisfaction and high support costs. Observability requires a modern approach to monitoring, and it’s more successful when developers buy in and participate in monitoring activities.
Here are some ideas for ramping up your observability practice in 2021:
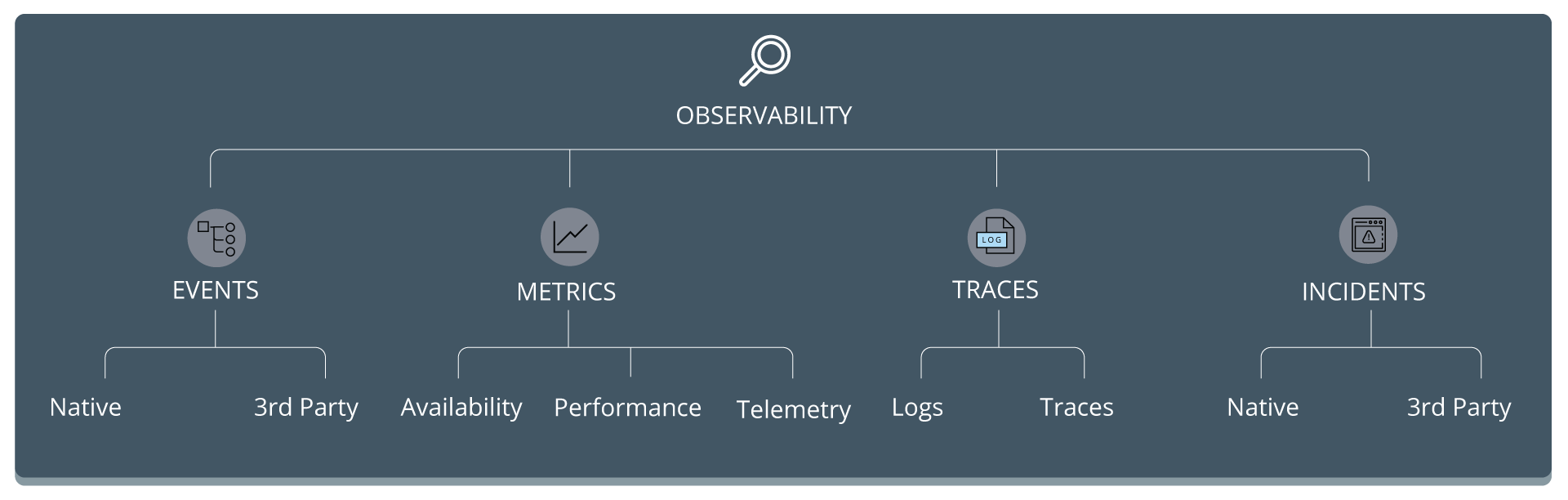
- Expand the data. Go beyond traditional resource monitoring metrics such as CPU utilization and network latency. Include logs, traces, metrics and alerts from every infrastructure component to allow for new insights into your application. Teams should have the proper routing and communication channels for when an incident occurs, and be able to quickly gain access to the system that can best remediate, or provide additional context.
- Make observability a development principle. Sorry, devs, but this is going to be part of your job sooner or later. Developers have been hearing for a while now that they can’t just “throw their code over the wall” and let operations people figure it out. Application health has long been owned by IT operations but logically speaking, the people who really understand application health are the developers because they built it and they know how code should work in production. Oftentimes, usually late in the sprint cycle, someone poses the question: “how are we going to monitor this service in production?” Dev teams rush around to get a workable solution and in the end, someone ends up running an instance of an open source monitoring tool on the app server(s). If this sounds familiar, you are not alone. This situation can be avoided by making observability a critical step in the CI/CD pipeline, and not an afterthought.
- Procure monitoring tools made for observability. APM tools or increasingly, open-source monitoring tools such as Prometheus can help measure operational metrics such as application, client, and server side errors that may occur during the normal operation of an application. Synthetics or digital experience management tools offer another way to understand the outputs of a system. This helps answer questions such as: can my user access the application and are there any transactional failures in her experience? There are some powerful, niche observability tools but they can be hard to use and require native monitoring expertise which many developers don’t have. Disregard the vendor buzz and adopt the tool that is right for your organization in terms of skill level, resources and so on. It should be easy to deploy and manage.
- Simplify tooling. A common pitfall spanning ITOps and DevOps organizations is the proliferation of duplicative tools. Data is often not federated between those tools, which can make the job of simply and comprehensively implementing an observability strategy a real pain. This is why it's so hard to achieve the vaulted single pane of glass. Most often, monitoring and observability tools are sought after and used to solve a pressing problem (like getting ready for a release, troubleshooting a specific client side error, etc). Over time, it’s easy to see how an organization can end up with more than 20 monitoring tools that solve overlapping use cases. Consolidate, integrate what you keep and consider a platform solution (like OpsRamp) to manage and unify all the data, saving time for both developers and operators.
- Rally around improving end user experience. Observability and the problems it solves are not just meaningful for developers, engineers and admins. Many of the insights generated by observability tools can provide rich context to less technical colleagues who may be working in sales, marketing, support, or professional services.
Some examples include:
- Which day(s), or time of year do we see the most traffic across our website?
- Is there a certain web page that users visit most often?
- After a launch, or web page change, are we seeing an increase in transactions?
- Is the web page loading slow, and if so, what are the contributing causes?
Answering these questions often bridges the tools that the non-technical teams have access to and requires deeper understanding of the application itself. DevOps and ITOps teams should collaborate with their non-technical stakeholders to understand what business problems can be addressed in observability tools, and the best way to solve them.
Next Steps:
- How to Overcome the 5 Top Challenges of Modern IT Operations
- Year in Review at OpsRamp
- Closer Look: Observability



