クラウドスケール管理の課題
ワークロードをパブリッククラウドインフラストラクチャに移行することで、IT運用チームの日常的な問題の多くが解決されます。 クラウド採用あり、CIOは、データセンター施設の管理、容量使用率の監視、またはエネルギー消費への取り組みについて心配する必要がなくなりました。ただし、パブリッククラウドサービスには、独自の一連の運用上の課題があります。
- 同じレベルの可視性と一貫性で、古い(オンプレミス)と新しい(クラウド)のワークロードをどのように監視しますか?
- さまざまなAWSサービスでアプリケーションを構築している場合、Amazonの可用性と耐久性のサービスレベル契約に沿って99.9%の稼働時間をどのように実現しますか?
パブリッククラウドサービスの弾力性、一時性、および弾力性の性質により、ITチームは可用性とパフォーマンス管理の観点からゲームを強化する必要があります。クラウドは「常時オンの可用性」を提供していると思われるかもしれませんが、実際には、クラウドインフラストラクチャは、データセンターで経験したのと同じ種類のテクノロジー障害の影響を受けます。多くのパブリッククラウドの停止 ヒューマンエラー(手動プロセスまたはコード展開の失敗)が原因です。有名なAWSS3の停止 2017年2月に発生しました。
クラウドプロバイダーは、問題認識と影響分析のためのさまざまな監視ツールを提供しています。 AWSの場合、CloudWatchは、メトリクスの追跡、ログのモニタリング、アラームの生成により、システム全体のヘルスとパフォーマンスを追跡するのに役立ちます。 AWS CloudWatchは、あらゆるタイプのAWSワークロードに対して豊富なモニタリングメトリクスを提供しますが、CloudWatchは実装が難しく、既存のプロセスに組み込むのが難しく、コスト面で予測できない場合があります。
CloudWatchがエンドツーエンドのモニタリングに重労働を必要とする理由
AWSプラットフォームで複数のアプリケーションを実行している企業の場合は、EC2、Lambda、S3、Glacier、VPC、Route 53、RDS、AuroraなどのさまざまなAWSサービスを使用している可能性があります。また、ディザスタリカバリの冗長性とコンテンツ配信の応答時間を短縮するために、さまざまなAWSリージョンでアプリケーションをホストする必要がある場合もあります。
CloudWatchを使用してAWSインフラストラクチャをモニタリングする際に考慮する必要のある実際的な課題は次のとおりです。
- 地域固有の構成。 異なるAWSリージョンでホストされているグローバルアプリケーションがある場合は、AWSリージョンごとに個別にCloudWatchモニタリングを設定する必要があります。アプリケーションを米国東部(バージニア州北部)、米国西部(カリフォルニア州北部)、EU(ロンドン)、およびアジア太平洋(シンガポール)にデプロイした場合は、CloudWatchメトリックス、ダッシュボード、アラーム、 4つのリージョンすべてのイベント設定。また、CloudWatchでは、さまざまなワークロードに対してさまざまなリージョンごとのメトリックスを組み合わせることができません。
- 手動アラーム設定。 まず、アラームポリシーを作成するために、AWSリソースのメトリックを個別に選択してから、CloudWatchでアラーム通知を手動で設定する必要があります。手動のスクリプトを使用せずに、CloudWatchアラーム設定を既存のワークロードまたは作成予定のワークロードにプッシュする自動化された方法はありません。
- 一般的な通知。 メールで、またはAmazon Simple Notification Service(SNS)またはAmazon Simple Queue Service(SQS)に通知を送信するようにCloudWatchを設定できます。ただし、AWSリージョンごとにCloudWatch通知を手動で設定する必要があります。また、CloudWatch通知を既存のインシデント、問題、および変更管理ワークフローとシームレスに統合することもできなくなります。
- 初歩的なアプリケーションインサイト。 Amazon CloudWatchは、エンタープライズアプリケーションを管理するためのすぐに使用できるモニタリングテンプレートを提供していません。アプリケーションメトリクスの詳細ログを集約する必要がある場合は、最初にCloudWatchエージェントをインストールしてから、手動設定を実行する必要があります。
OpsRampを使用してAWSインスタンスの制御を取得します
OpsRampのマルチテナントSaaSプラットフォーム 一般的な運用プロセスを拡張できます(発見、 モニタリング、イベント相関、およびアラート)DevOpsチームに余分な負担をかけることなく、クラウドインフラストラクチャに対応します。 OpsRampで異なるチームに複数のテナントを作成し、各テナントで複数のAWSアカウント、リソース、およびポリシーをオンボードできます。また、AWSリソースのプロアクティブな監視と企業全体の可視性のために、各テナントに無制限のAWSアカウントを設定することもできます。
OpsRampを使用すると、クラウドフットプリント全体でITの停止を迅速に検出して処理し、ビジネスにとって重要な問題に迅速に対応できます。 AWS CloudWatchメトリクスをOpsRampのデジタルオペレーションコマンドセンターと組み合わせて、エンドユーザーに影響を与える前に問題を診断して解決できるようにします。
- リアルタイム分析。 すべてのCloudWatchメトリクスをOpsRampに取り込んで保存し、クラウドアプリケーションの可用性と正常性に関する統一されたリアルタイムの洞察を得ます。
- 即時の可視性。CloudWatchとCloudTrailのログとアラートをAPIを介してOpsRampにストリーミングします。 CloudWatchメトリクスのOpsRampAPIクエリの総数に制限はありません。
- データ保持。 CloudWatchメトリクスデータ全体をOpsRampに12か月間保持します。コンプライアンスの目的でCloudWatchのデータ保持を拡張することもできます。
- 包括的なアプリの監視。 エンタープライズアプリケーション向けのOpsRampのネイティブモニタリング機能を使用して、基本的なEC2CloudWatchメトリクスを補完します。
- 効率的なクラウド運用。 OpsRampの自動化管理フレームワークを使用して、クラウド運用を合理化し、インシデントの修復を大規模に処理します。
OpsRampは、管理されているAWSリソースの数に基づいて、シンプルで透過的な価格設定を提供します。リソースベースの価格設定には、メトリック、アラーム、イベント、およびダッシュボードの個別の制限なしで、すべてのプラットフォーム機能が含まれます。
OpsRampを使用してAWSCloudWatchの機能を拡張する
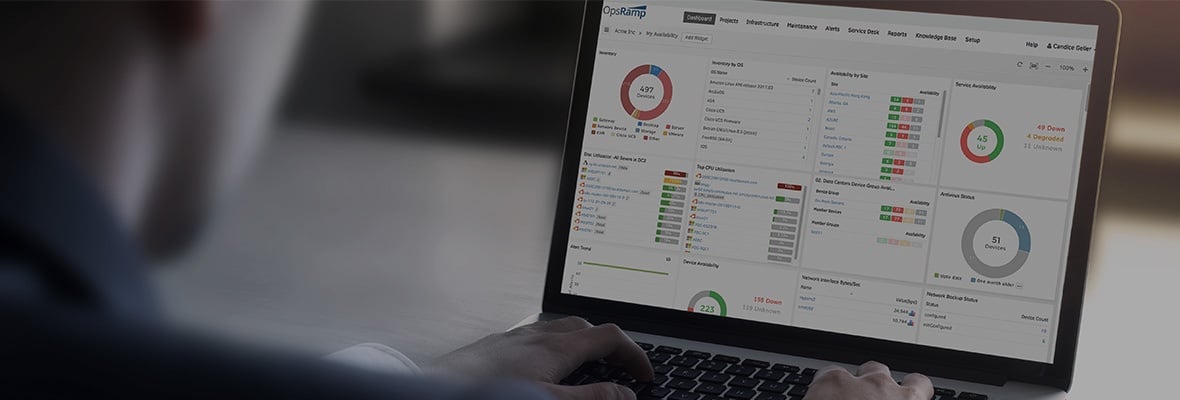
OpsRampでAWSリソースを効果的に監視することで、クラウドワークロードのパフォーマンスをリアルタイムで追跡し、停止を防ぎます。パブリッククラウドの消費の可視性を高め、すべてのクラウドサービスの信頼できる唯一の情報源を実現できます。 AWSCloudWatchメトリクスをOpsRampのメトリクスと組み合わせる利点は次のとおりですハイブリッドインフラストラクチャ管理プラットフォーム:
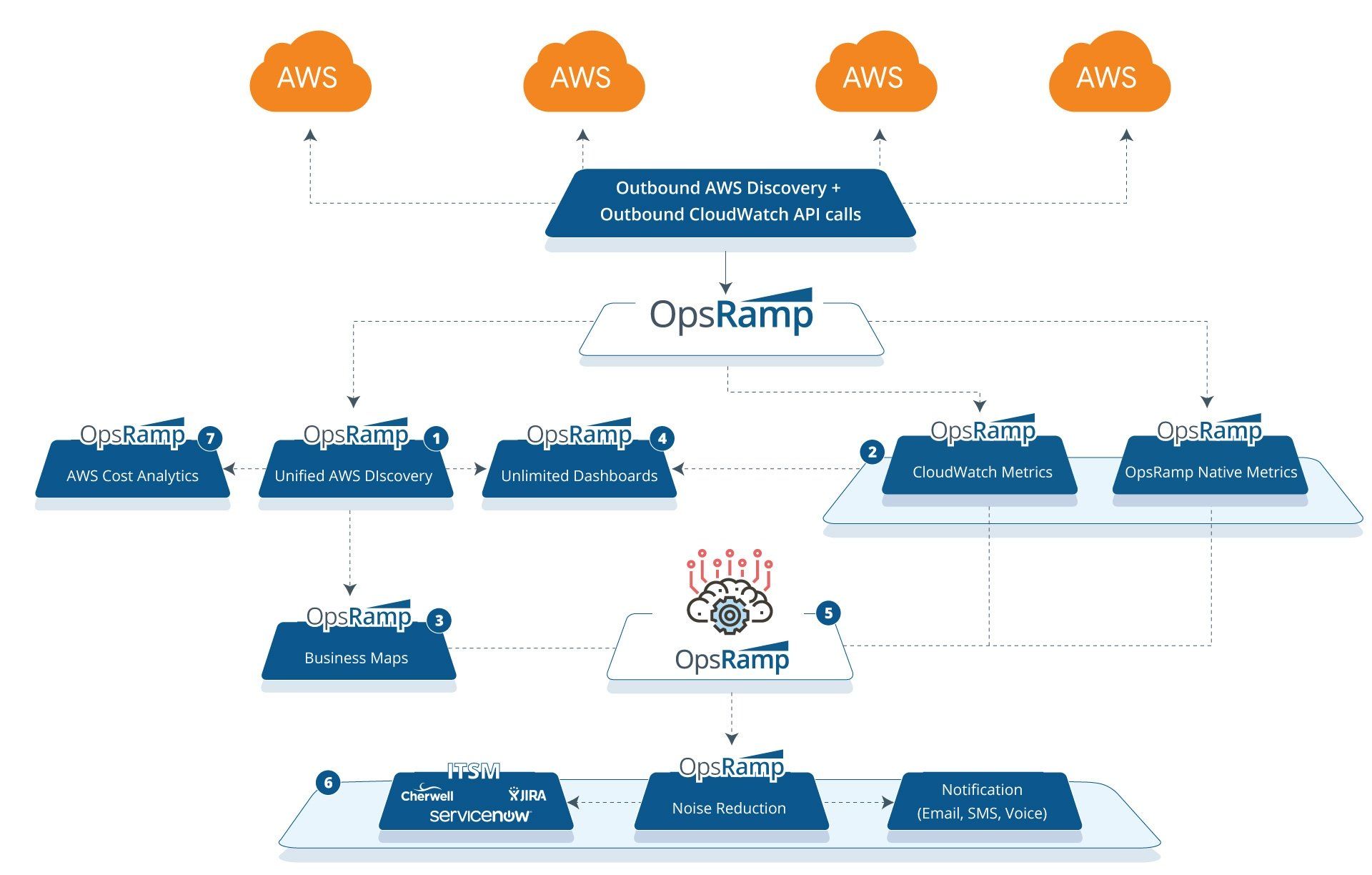
図1-OpsRampを使用してAWSスタック全体を1か所で管理します。
- 統合ディスカバリー。 すべてのAWSアカウントをOpsRampにオンボードし、クラウドインフラストラクチャを動的に検出します。すべてのCloudWatchおよびCloudTrailキューをOpsRampにストリーミングして、クラウドインフラストラクチャをプロアクティブに可視化します。
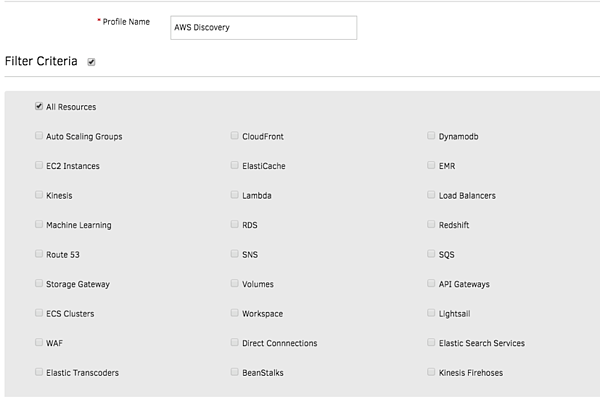
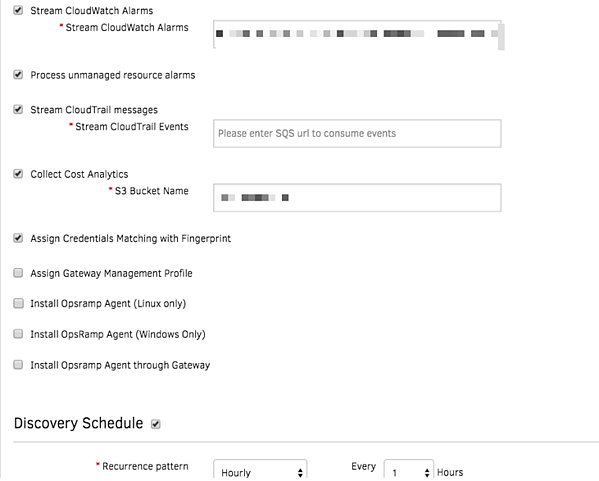 図2-UnifiedServiceDiscoveryを使用して動的AWSリソースを検出してオンボードします。
図2-UnifiedServiceDiscoveryを使用して動的AWSリソースを検出してオンボードします。
- スマート管理ポリシー。OpsRampのポリシーを使用して、CloudWatchメトリクスを自動的に収集し、OpsRampエージェントによって収集されたメトリクスと組み合わせます。当社のアプリケーションモニターは、クラウドエステートの包括的なビューとともに、アプリケーションの状態とパフォーマンスに適切なコンテキストを提供します。
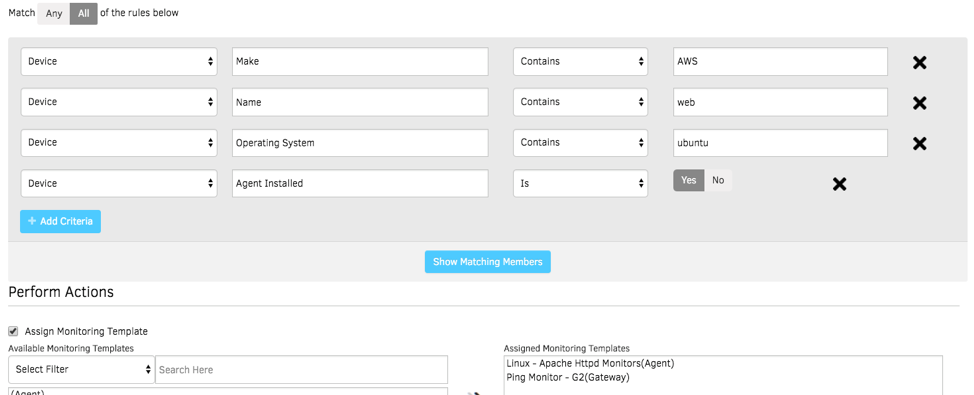
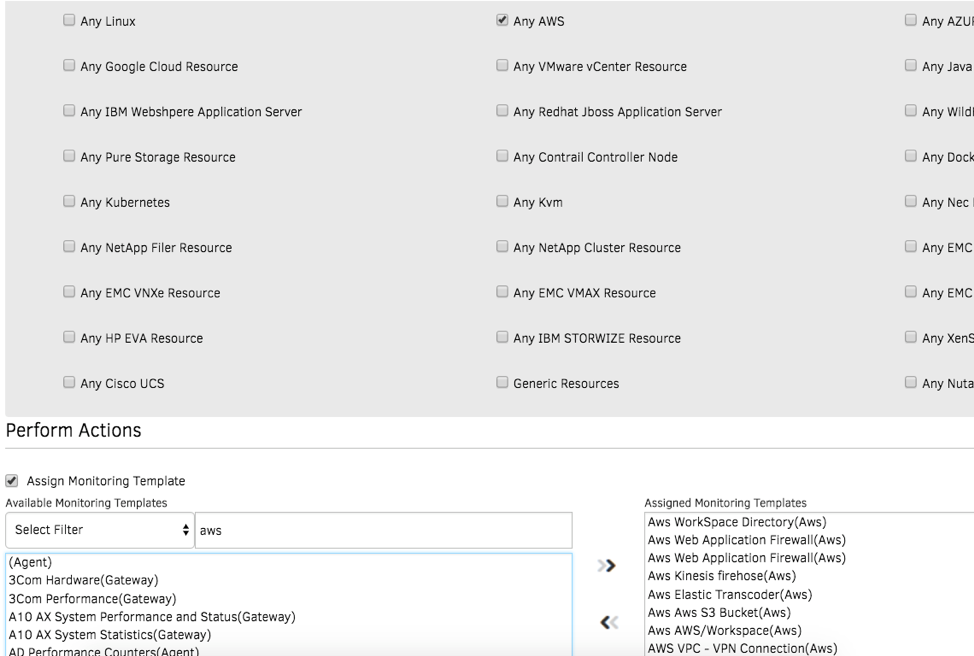
図3-スマートポリシーは、クラウドインフラストラクチャの稼働時間とパフォーマンスを管理します。
- サービス中心の可視性。AWSリソースのサービスマップを作成して、見通し内の可視性とIT停止の影響分析を高速化します。メトリックとアラートをサービスマップビューに統合して、ビジネスクリティカルなサービスをより適切に管理します。
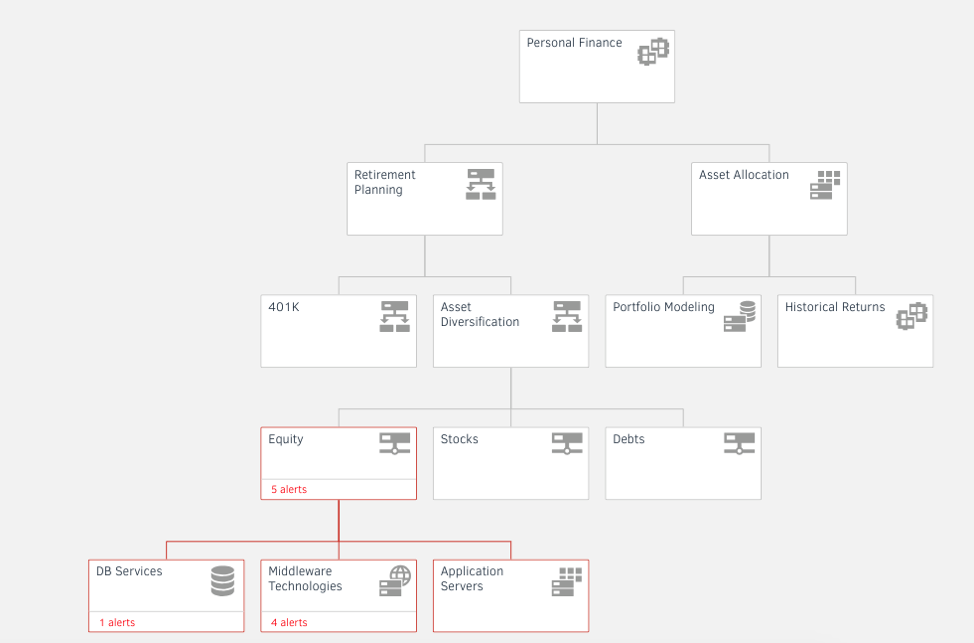
図4-サービスマップを使用してアプリケーションとAWSリソースの依存関係を追跡します。 - リアルタイムダッシュボード。OpsRampで無制限のダッシュボードを作成して、すべてのCloudWatchメトリクスとログに関連するパフォーマンスインサイトを抽出します。を使用して、クラウドサービスの可視性と洞察までの時間を短縮します。カスタマイズ可能な役割ベースのダッシュボード。
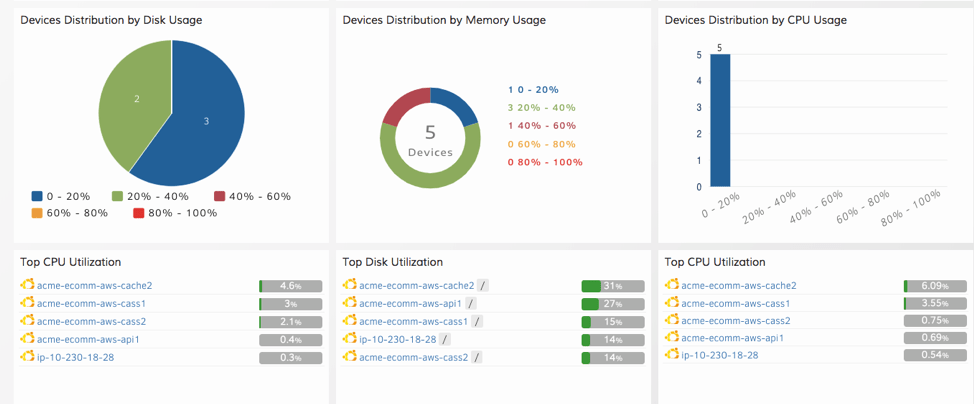
図5-より優れた視覚化と分析でAWSインフラストラクチャを管理します。 - 推論エンジン。AIOps推論エンジンはCloudWatchから生のイベントとアラートを取り込み、高度な分析とトポロジベースのイベント相関を使用してITインシデントの根本原因を特定するのに役立ちます。アラートノイズを減らすだけでなく、適切なコンテキストと自信を持ってITの停止をトラブルシューティングすることもできます。
- アラート管理。ターゲットルーティングを使用して、コンテキストが注入されたアラート通知をオンコールオペレーターに送信します。電子メール、音声、テキスト、チャットなど、さまざまな通信チャネルを使用して通知をプッシュできます。何よりも、サービスデスクでインシデントを作成し、堅牢なITSMツール統合を使用して問題を解決するために管理します。
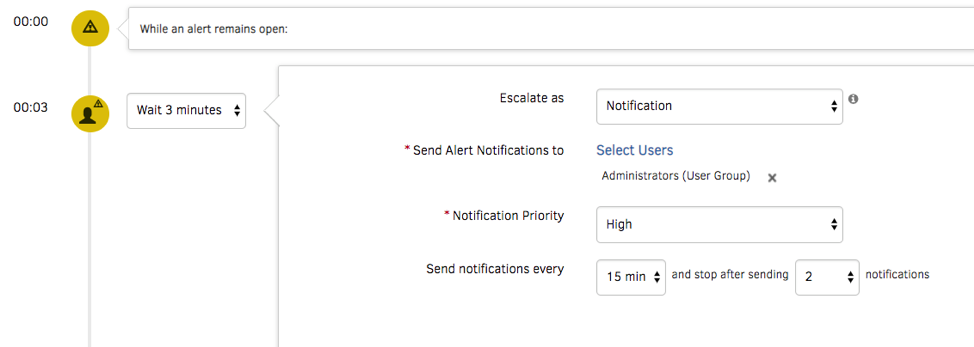
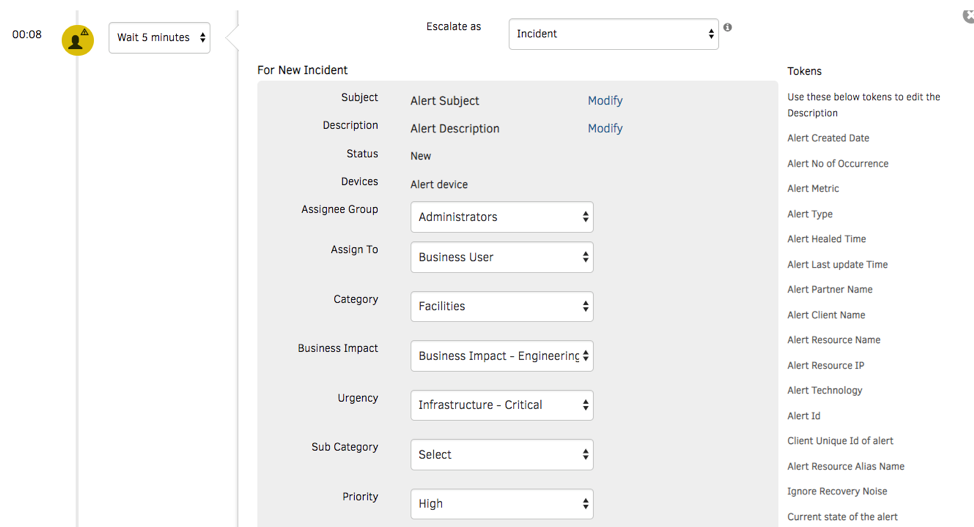
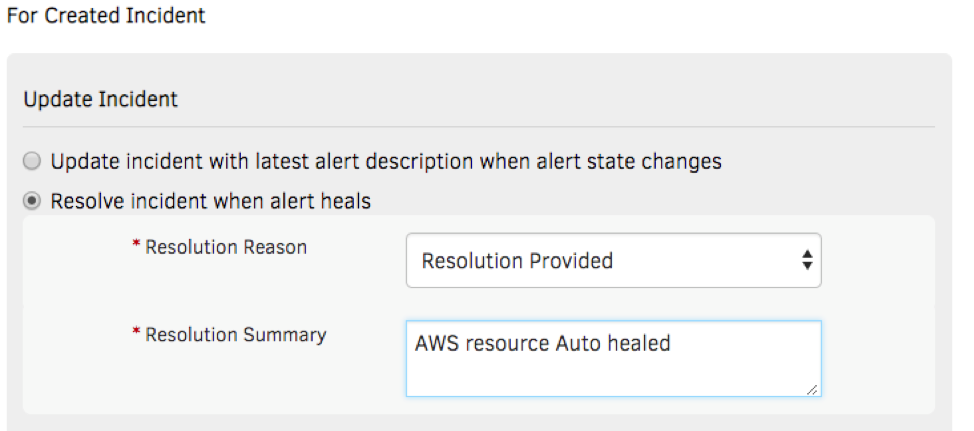
図6-ジャストインタイムのアラート通知を使用して、サービスを迅速に復元します。 - コスト動向と予算方針。OpsRampは、AWS S3コストバケットから直接コストデータを消費するため、最新のコストインサイトにアクセスできます。 Cloud Cost Trendsウィジェットは、アカウント、リージョン、AWSタグ、リソースタイプなどごとにコストデータをスライスアンドダイスできます。 OpsRampに予算ポリシーを実装して、クラウドの支出が指定された予算のしきい値を超えた場合に警告または重大なアラームとして機能します。

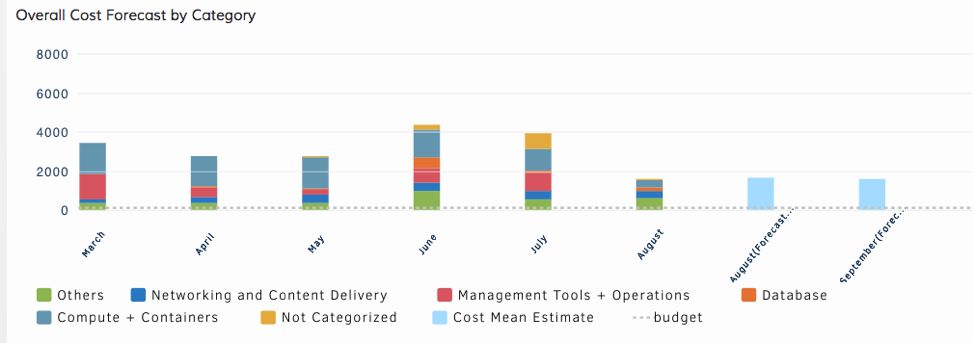
図6-AWSエステート全体のコストと支出に関する洞察に1か所でアクセスできます。
次のステップ:
- クラウド運用を拡張するOpsRampのパフォーマンスとコストに関する洞察.
- あなたを構築する 適切な組織スキルを備えたクラウド基盤。
- 自信を持ってマルチクラウド管理を採用したい場合は、今日、OpsRampソリューションコンサルタントに相談してください。
![[Report] Top Trends In AIOps Adoption](https://blog.opsramp.com/hs-fs/hubfs/Blog_images/AIOps%20Adoption%20Report%20/CTA-AIOps-Adoption.jpg?width=1180&name=CTA-AIOps-Adoption.jpg)